
Trigger Analysis via API
This document aims to guide how to trigger analysis execution through TCA APIs.
Application Scenarios
Can be encapsulated into an API script to trigger analysis by calling the API as needed.
Can be encapsulated into a CI plugin and integrated into the CI pipeline to trigger analysis.
Guide to Triggering Code Analysis
Overall Process
By calling the API, register the code repository into the TCA platform, create an analysis project based on configurations such as the analysis scheme, and then trigger code analysis. TCA schedules the task to run code analysis on node machines and retrieves the analysis task results through polling. Finally, determine whether the quality gate passes based on the quality gate information in the results, and obtain detailed task execution information and issue lists.
Hierarchy Description
Team -> Project -> Code Repository -> Analysis Project (composed of branch + analysis path + analysis scheme to form a unique analysis project).
Create a project group. If it already exists, use it directly without creation.
Register the code repository. If it already exists, use it directly without registration.
Create an analysis project. If it already exists, use it directly without creation.
Start the analysis task.
Poll the task status to determine if the task execution succeeded/failed.
Obtain analysis results, quality gate information, etc.
Obtain code inspection issue data.
Prerequisite Steps
Overview of Prerequisite Steps
Get API Access Token: Required for API interface authentication, including
user_idandtoken.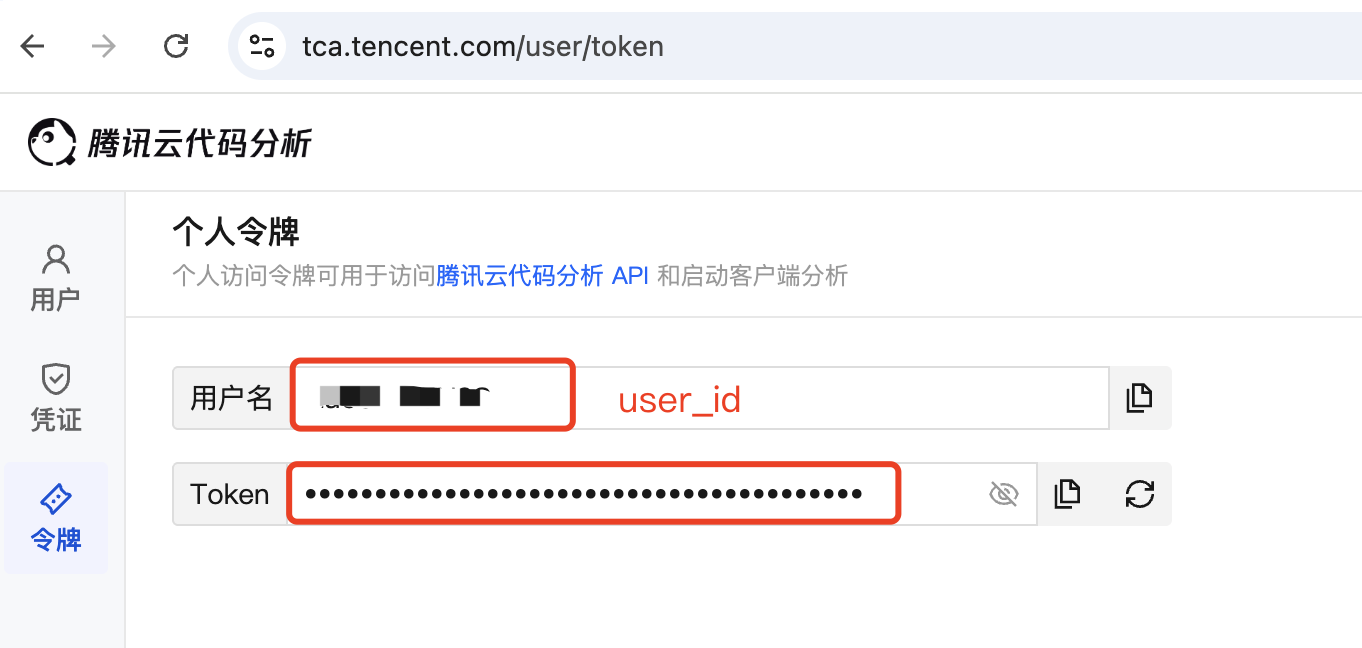
Get Code Repository Credential ID: Required for registering the code repository, used to pull code when executing analysis, i.e.,
scm_account_id. If it does not exist, create a credential.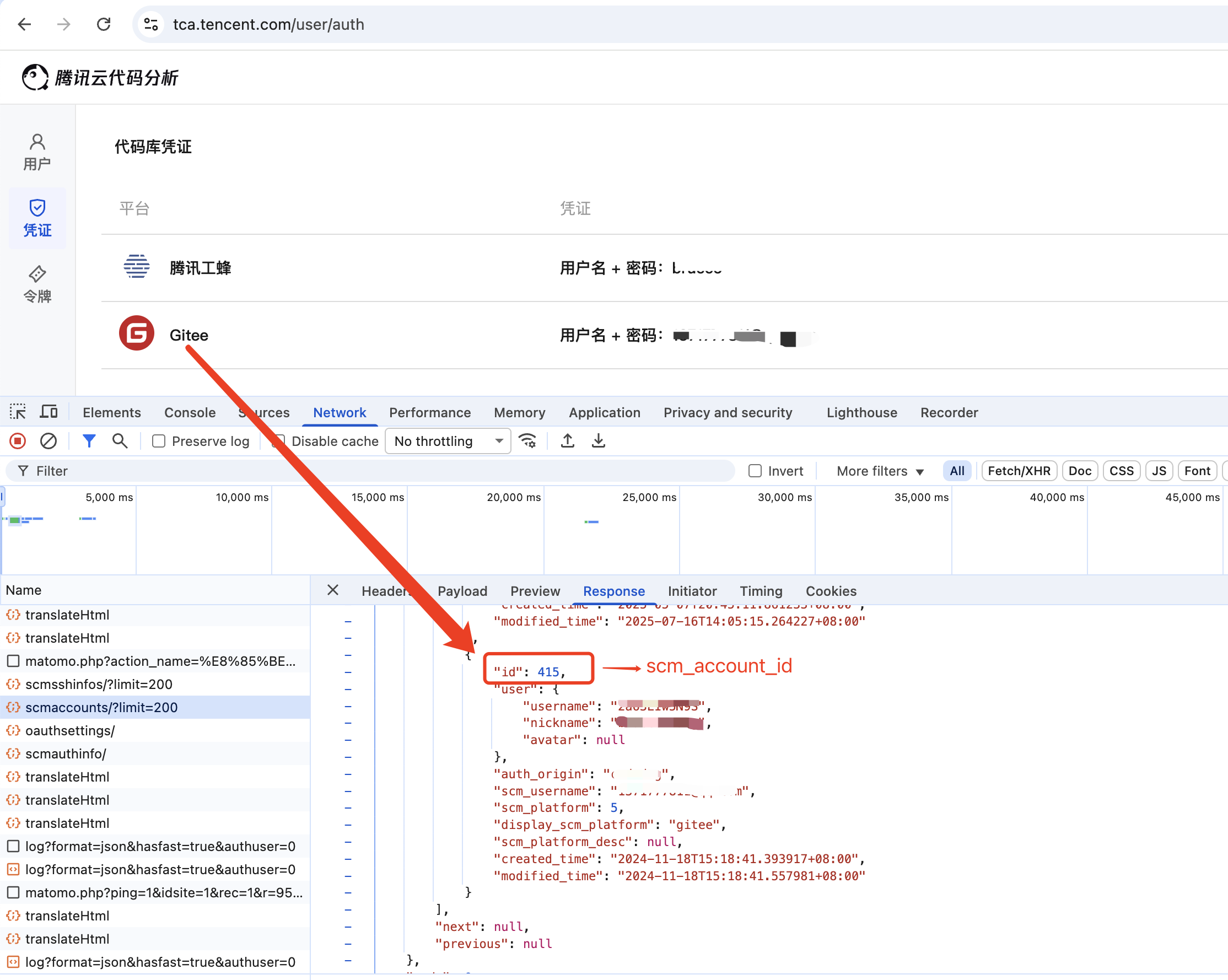
Get Analysis Scheme ID: Required for creating an analysis project. You can obtain
scheme_idfrom the Analysis Scheme - Basic Configuration page or the URL link. If it does not exist, create a team/project analysis scheme as needed.Integrate Online Node: Required for executing code analysis. Essentially, tasks triggered via API are executed on TCA online nodes. Ensure that TCA has available online nodes; otherwise, analysis will fail due to no available nodes.
API Invocation Process
For API interface authentication, refer to the document: API Interface Authentication
1. Create Project Group
It is recommended to first check if the project group exists. If not, create it; if it exists, use it directly.
GET|POST /server/main/api/orgs/{org_sid}/teams/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/" post_data = { "name": team_name, "display_name": team_name } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
2. Register Code Repository
It is recommended to first check if the corresponding code repository exists. If not, register it; if it exists, use it directly.
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/" post_data = { "scm_url": repo_url, "scm_type": "git", "scm_auth": { "auth_type": "password", "scm_account": scm_account_id }, "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
3. Create Analysis Project
It is recommended to first check if the corresponding analysis project exists. If not, create it; if it exists, use it directly.
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/" post_data = { "branch": repo_branch, "global_scheme_id": scheme_id, "use_scheme_template": True, "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
4. Start Analysis Task
POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scans/create/
Normal Trigger
post_data = { "incr_scan": True, # Whether to perform incremental scan (False for full scan, True for incremental) }Merge Request Trigger
post_data = { "incr_scan": True, # Whether to perform incremental scan (False for full scan, True for incremental) "ignore_branch_issue": "target_branch", # Target branch for comparison "ignore_merged_issue": True }
import requests
url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scans/create/"
headers = get_headers(user_id, token)
resp = requests.post(url, json=post_data, headers=headers)
result = resp.json()
print(result)
5. Poll Task Status
GET /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/
Get Task Details API: Poll the scan status until state == 2:
6. Get Analysis Results
After scanning completes, the interface returns a complete scan results object results[0] containing multi-dimensional scan data.
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/
Get Analysis Overview List API:
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
results = result.get("data", {}).get("results", [])
print(result[0])
6.1. Code Inspection Results (lintscan)
lint = result[0].get("lintscan", {})
print({
"issue_open_num": lint.get("issue_open_num"),
"issue_fix_num": lint.get("issue_fix_num"),
"issue_detail_num": lint.get("issue_detail_num"),
})
6.2. Cyclomatic Complexity Results (cyclomaticcomplexityscan)
cc = result[0].get("cyclomaticcomplexityscan", {})
print({
"diff_cc_num": cc.get("diff_cc_num"),
"cc_open_num": cc.get("cc_open_num"),
})
6.3. Duplicate Code Results (duplicatescan)
dup = result[0].get("duplicatescan", {})
print({
"duplicate_block_count": dup.get("duplicate_block_count"),
"total_duplicate_line_count": dup.get("total_duplicate_line_count"),
})
6.4. Code Statistics Results (clocscan)
cloc = result.get("clocscan", {})
print({
"code_line_num": cloc.get("code_line_num"),
"comment_line_num": cloc.get("comment_line_num"),
"blank_line_num": cloc.get("blank_line_num"),
"total_line_num": cloc.get("total_line_num"),
})
6.5. Get Quality Gate Status (Quality Gate)
quality = result[0].get("qualityscan", {})
status = quality.get("status") # "success": Gate passed, "failure": Gate failed, "close": Gate not enabled
description = quality.get("description")
if status == "success":
print("Quality gate passed")
elif status == "close":
print("Quality gate not enabled")
else:
print(f"Quality gate failed: {description}")
7. Get Code Inspection Issue Data
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/
import requests
import json
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
print(json.dumps(result, indent=2, ensure_ascii=False))
Script Reference
Environment Variables
When executing the script, environment variables can be injected to dynamically adjust parameters and achieve automated integration.
# TCA platform service address
TCA_BASE_URL=https://tca.tencent.com
# API access token
TCA_USER_ID=your_user_id
TCA_TOKEN=your_token
# Unique identifier of the team
TCA_ORG_SID=your_org_sid
# Unique identifier of the project group
TCA_TEAM_NAME=your_team_name
# Code repository URL
TCA_REPO_URL=your_repo_url
# Code repository credential ID
TCA_SCM_ACCOUNT_ID=your_scm_account_id
# Analysis scheme ID (can use team/project analysis scheme, note permission issues)
TCA_SCHEME_ID=your_scheme_id
# Branch name
TCA_REPO_BRANCH=your_repo_branch
# Whether to perform incremental scan
TCA_INCR_SCAN=true
# Whether to ignore issues in specified code repository branches
TCA_IGNORE_MERGED_ISSUE=true
# Target branch for merge request scenarios
TCA_IGNORE_BRANCH_ISSUE=your_ignore_branch
Script Content
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Start code analysis via API
"""
import os
import sys
import json
import requests
import logging
from typing import Dict, List, Optional, Any, Tuple
from dataclasses import dataclass
from time import time, sleep
from hashlib import sha256
# Log configuration
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout),
logging.FileHandler('tca_ci_pipeline_saas.log')
]
)
logger = logging.getLogger(__name__)
# OpenAPI path mapping
TCA_OPEN_APIS = {
"project_team_list": "%s/server/main/api/orgs/{org_sid}/teams/",
"pt_repo_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/",
"project_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/",
"project_scan_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scans/create/",
"job_detail": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/",
"project_analysis_scan_list": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/",
"project_issue_list": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/",
}
@dataclass
class TCAConfig:
"""TCA Configuration Class"""
base_url: str
tca_token: str
user_id: str
org_sid: str
team_name: str
repo_url: str
repo_branch: str
repo_mr_branch: str
scm_account_id: int
scheme_id: int
incr_scan: bool
ignore_merged_issue: bool
ignore_branch_issue: str
timeout: int = 30
max_retries: int = 3
class TCAIntegrationError(Exception):
"""TCA Integration Exception"""
pass
class TCAClient:
"""TCA API Client"""
def __init__(self, config: TCAConfig):
self.config = config
self.session = requests.Session()
def get_headers(self, user_id: Optional[str] = None, token: Optional[str] = None):
timestamp = int(time())
user_id = user_id or self.config.user_id
token = token or self.config.tca_token
token_sig = "%s%s#%s#%s%s" % (timestamp, user_id, token, user_id, timestamp)
ticket = sha256(token_sig.encode("utf-8")).hexdigest().upper()
return {
"TCA-USERID": user_id,
"TCA-TIMESTAMP": str(timestamp),
"TCA-TICKET": ticket
}
def _is_success_status(self, status_code: int) -> bool:
"""Determine if HTTP status code indicates success (2xx)"""
return 200 <= status_code < 300
def _make_request(self, method: str, url: str, data: Optional[Dict] = None,
params: Optional[Dict] = None) -> Dict:
"""Send API request (url must be a full path)"""
for attempt in range(self.config.max_retries):
try:
headers = self.get_headers()
response = self.session.request(
method=method,
url=url,
headers=headers,
json=data,
params=params,
timeout=self.config.timeout
)
if self._is_success_status(response.status_code):
return response.json()
elif response.status_code == 401:
raise TCAIntegrationError("Invalid or expired TCA Token")
elif response.status_code == 403:
raise TCAIntegrationError("Insufficient permissions, please check team ID and permission settings")
elif response.status_code == 404:
raise TCAIntegrationError("Requested resource does not exist")
elif response.status_code >= 500:
logger.warning(f"Server error, retrying ({attempt + 1}/{self.config.max_retries})...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("Internal server error, please try again later")
sleep(2 ** attempt) # Exponential backoff
else:
raise TCAIntegrationError(f"API request failed: {response.status_code} - {response.text}")
except requests.exceptions.Timeout:
logger.warning(f"Request timed out, retrying ({attempt + 1}/{self.config.max_retries})...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("Request timed out, please check network connection")
except requests.exceptions.ConnectionError:
logger.warning(f"Connection error, retrying ({attempt + 1}/{self.config.max_retries})...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("Network connection error, please check network settings")
def _build_url(self, key: str, **kwargs: Any) -> str:
base = self.config.base_url.rstrip('/')
tpl = TCA_OPEN_APIS[key] % base
return tpl.format(**kwargs)
def get_project_teams(self) -> Dict:
url = self._build_url("project_team_list", org_sid=self.config.org_sid)
return self._make_request("GET", url)
def get_pt_repos(self) -> Dict:
url = self._build_url("pt_repo_list", org_sid=self.config.org_sid, team_name=self.config.team_name)
return self._make_request("GET", url)
def get_pt_repo_id(self, repo_url: Optional[str] = None) -> int:
"""Get the ID of the corresponding repository under the team based on the repository URL (exact match only).
Precisely compares `scm_url`, raises TCAIntegrationError if not found.
"""
result = self.get_pt_repos()
data = result.get("data") or {}
results = data.get("results") or []
repo_url = repo_url or self.config.repo_url
if not isinstance(results, list):
raise TCAIntegrationError("Failed to get team repository list, incorrect return format")
for item in results:
if not isinstance(item, dict):
continue
if repo_url == item.get("scm_url") or repo_url == item.get("format_url"):
repo_id_val = item.get("id")
if repo_id_val is not None:
return int(repo_id_val)
raise TCAIntegrationError(f"Repository {repo_url} not found under project group {self.config.team_name}")
def create_project_team(self) -> Dict:
"""Create a project group"""
logger.info(f"Creating project group: {self.config.team_name}")
url = self._build_url("project_team_list", org_sid=self.config.org_sid)
post_data = {
'name': self.config.team_name,
'display_name': self.config.team_name
}
result = self._make_request("POST", url, data=post_data)
return result
def register_pt_repo(self) -> Dict:
"""Register a code repository (at the project group level)"""
logger.info(f"Project group: {self.config.team_name}, creating code repository: {self.config.repo_url}")
url = self._build_url("pt_repo_list", org_sid=self.config.org_sid, team_name=self.config.team_name)
post_data = {
'scm_url': self.config.repo_url,
'scm_type': "git",
'scm_auth': {
"auth_type": "password",
"scm_account": self.config.scm_account_id
},
'created_from': "api"
}
result = self._make_request("POST", url, data=post_data)
return result
def create_project(self) -> Dict:
"""Create an analysis project"""
logger.info(f"Project group: {self.config.team_name}, creating analysis project for code repository: {self.config.repo_url}")
repo_id = self.get_pt_repo_id(self.config.repo_url)
url = self._build_url("project_list", org_sid=self.config.org_sid, team_name=self.config.team_name,
repo_id=repo_id)
post_data = {
'branch': self.config.repo_branch,
'global_scheme_id': self.config.scheme_id,
'use_scheme_template': True,
'created_from': "api"
}
result = self._make_request("POST", url, data=post_data)
return result
def get_projects(self) -> Dict:
repo_id = self.get_pt_repo_id(self.config.repo_url)
url = self._build_url("project_list", org_sid=self.config.org_sid, team_name=self.config.team_name,
repo_id=repo_id)
return self._make_request("GET", url)
def get_project_id(self, scheme_id: Optional[int] = None, branch: Optional[str] = None) -> int:
"""Get the analysis project ID based on scan_scheme.id and branch.
- Precisely matches `scan_scheme.id` and `branch` from the project list
"""
scheme_id = scheme_id or self.config.scheme_id
branch = branch or self.config.repo_branch
logger.info(f"scheme_id={scheme_id}, branch={branch}")
result = self.get_projects()
data = result.get("data") or {}
results = data.get("results") or []
if not isinstance(results, list):
raise TCAIntegrationError("Failed to get project list, incorrect return format")
for item in results:
if not isinstance(item, dict):
continue
item_scheme = (item.get("scan_scheme") or {}).get("id")
item_branch = item.get("branch")
if int(item_scheme) == int(scheme_id) and item_branch == branch:
proj_id = item.get("id")
if proj_id is not None:
return int(proj_id)
raise TCAIntegrationError(f"No matching analysis project found, scheme_id={scheme_id}, branch={branch}")
def start_scan(self) -> Dict:
"""Start a scan task"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_scan_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
incr_scan = self.config.incr_scan
ignore_branch_issue = self.config.ignore_branch_issue
ignore_merged_issue = self.config.ignore_merged_issue
post_data = {
'incr_scan': incr_scan,
'ignore_branch_issue': ignore_branch_issue,
'ignore_merged_issue': ignore_merged_issue
}
result = self._make_request("POST", url, data=post_data)
return result
def wait_for_scan_completion(self, job_id: int) -> Dict:
"""Wait for the analysis task status to become 2 (completed)"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("job_detail", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id, job_id=job_id)
max_wait_time = 600 # Maximum wait time 10 minutes (600 seconds, customizable)
interval = 30 # Check every 30 seconds
start_time = int(time())
while True:
results = self._make_request("GET", url)
# Get data from results
data = results.get("data", {})
if data:
state = data.get("state")
if state == 2:
logging.info("Scan results are available, stopping wait")
break # Exit loop as condition is met
elapsed = int(time()) - start_time
if elapsed > max_wait_time:
logger.info(f"Scan exceeded {max_wait_time} seconds, status unchanged, scan failed")
raise TCAIntegrationError(f"Scan exceeded {max_wait_time} seconds, status unchanged, scan failed")
logging.info(
f"Code is being scanned (current state: {data.get('state') if data else 'no data'}), retrying in 30 seconds...")
sleep(interval)
return results
def get_scan_info(self) -> Dict:
"""Get the latest analysis results information"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_analysis_scan_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
response = self._make_request("GET", url)
results = response.get("data", {}).get("results", [])
return results[0]
def get_issue_list(self) -> Dict:
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_issue_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("GET", url)
return result
class TCAPipeline:
"""TCA Pipeline Integration Class"""
def __init__(self, config: TCAConfig):
self.client = TCAClient(config)
self.config = config
def run_full_analysis(self) -> bool:
"""Run the full analysis process"""
# 1. Create project group (or reuse existing project_team)
exist_project_teams = self.client.get_project_teams()
if not self.has_team_name(exist_project_teams, self.config.team_name):
project_team = self.client.create_project_team()
# 2. Register code repository (or reuse existing repo)
try:
self.client.get_pt_repo_id(self.config.repo_url)
except TCAIntegrationError as e:
logger.info(f"Existing code repository not found: {self.config.repo_url}, creating new repository")
self.client.register_pt_repo()
# 3. Create project under this repo (or reuse existing project)
try:
self.client.get_project_id()
except TCAIntegrationError as e:
logger.info(f"Existing project not found: {self.config.repo_url}, creating new project")
self.client.create_project()
# 4. Start scan
start_scan_result = self.client.start_scan()
job_id = self.get_job_id(start_scan_result)
# 5. Wait for completion
try:
scan_result = self.client.wait_for_scan_completion(job_id)
except TCAIntegrationError as e:
logger.error(f"Scan failed: {e}")
return False
# 5. If no code changes, incremental scan will show result_code=1, indicating no scan needed
result_code, result_code_msg, result_msg = self.get_result_msg(scan_result)
if result_code == 1:
logger.info(
f"No code changes, result_code: {result_code}, result_code_msg: {result_code_msg}, result_msg: {result_msg} - scan info is from the last scan")
elif result_code == 0:
logger.info(
f"Code changes detected, result_code: {result_code}, result_code_msg: {result_code_msg}, result_msg: {result_msg} - scan info is from the latest scan")
elif result_code >= 100:
logger.error(f"Scan failed: {result_code}, {result_code_msg}, {result_msg}")
return False
scan_info = self.client.get_scan_info()
# 5. Get code scan results
lint_scan_result = self.get_lint_scan_result(scan_info)
logger.info(f"Code scan results: {lint_scan_result}")
# 6. Get cyclomatic complexity results
cyclomatic_complexity_result = self.get_cyclomatic_complexity_result(scan_info)
logger.info(f"Cyclomatic complexity results: {cyclomatic_complexity_result}")
# 7. Get duplicate code results
duplicate_code_result = self.get_duplicate_code_result(scan_info)
logger.info(f"Duplicate code results: {duplicate_code_result}")
# 8. Get code statistics results
get_cloc_result = self.get_cloc_result(scan_info)
logger.info(f"Code statistics results: {get_cloc_result}")
# 9. Get issue list
issues = self.client.get_issue_list()
logger.info(f"Issue list: {issues}")
# 10. Get quality gate results
quality_gate_result = self.get_quality_gate_result(scan_info)
logger.info(f"Quality gate results: {quality_gate_result}")
if quality_gate_result.get("status") == "success" or quality_gate_result.get("status") == "close":
return True
else:
return False
def get_job_id(self, result: dict) -> int:
try:
job_id = result["data"]["job"]["id"]
except (KeyError, TypeError):
raise TCAIntegrationError("Incorrect response format, data.job.id not found")
return job_id
def get_result_msg(self, result: dict) -> Tuple[int, str, str]:
try:
result_code = result["data"]["result_code"]
result_code_msg = result["data"]["result_code_msg"]
result_msg = result["data"]["result_msg"]
except (KeyError, TypeError):
raise TCAIntegrationError("Incorrect response format, data.result_code information not found")
return result_code, result_code_msg, result_msg
def get_lint_scan_result(self, results: dict) -> dict:
"""Get code scan results (lintscan)"""
lint = results.get("lintscan") or {}
return {
"issue_open_num": lint.get("issue_open_num"),
"issue_fix_num": lint.get("issue_fix_num"),
"issue_detail_num": lint.get("issue_detail_num"),
}
def get_cyclomatic_complexity_result(self, results: dict) -> dict:
"""Get cyclomatic complexity results (cyclomaticcomplexityscan)"""
cc = results.get("cyclomaticcomplexityscan") or {}
return {
"diff_cc_num": cc.get("diff_cc_num"),
"cc_open_num": cc.get("cc_open_num"),
}
def get_duplicate_code_result(self, results: dict) -> dict:
"""Get duplicate code results (duplicatescan)"""
dup = results.get("duplicatescan") or {}
return {
"duplicate_block_count": dup.get("duplicate_block_count"),
"total_duplicate_line_count": dup.get("total_duplicate_line_count"),
}
def get_cloc_result(self, results: dict) -> dict:
"""Get code statistics results (clocscan)"""
cloc = results.get("clocscan") or {}
return {
"code_line_num": cloc.get("code_line_num"),
"comment_line_num": cloc.get("comment_line_num"),
"blank_line_num": cloc.get("blank_line_num"),
"total_line_num": cloc.get("total_line_num"),
}
def get_quality_gate_result(self, results: dict) -> dict:
"""Get quality gate status (qualityscan)"""
quality = results.get("qualityscan") or {}
return {
"status": quality.get("status"),
"description": quality.get("description"),
}
def has_team_name(self, response: dict, team_name: str) -> bool:
"""
Determine if there is a project group with name == team_name in the returned project_team data.
:param response: Complete dictionary data returned by the interface
:return: True if a team named team_name exists, otherwise False
"""
try:
teams = response.get("data", [])
for team in teams:
if team.get("name") == team_name:
return True
return False
except Exception as e:
TCAIntegrationError(f"Error parsing team data: {e}")
return False
def _manual_load_dotenv(candidates: List[str]) -> int:
"""Simple .env parser: Manually load KEY=VALUE into os.environ if python-dotenv is not installed.
Only overrides variables that are not already set. Returns the number of successfully loaded variables."""
loaded = 0
for path in candidates:
if not path:
continue
if os.path.exists(path) and os.path.isfile(path):
try:
with open(path, 'r', encoding='utf-8') as f:
for raw_line in f:
line = raw_line.strip()
if not line or line.startswith('#'):
continue
if '=' not in line:
continue
key, val = line.split('=', 1)
key = key.strip()
val = val.strip().strip('"').strip("'")
if key and key not in os.environ:
os.environ[key] = val
loaded += 1
logger.info(f"Loaded {loaded} variables from .env: {path}")
except Exception as e:
logger.warning(f"Failed to read .env: {path} - {e}")
return loaded
def str_to_bool(value: str) -> bool:
"""Convert a string to a boolean value (case-insensitive)"""
return str(value).strip().lower() in ['true', '1', 't', 'y', 'yes']
def load_config_from_env() -> TCAConfig:
"""Load configuration only from environment variables and .env files (no longer reads config.py).
Priority: Process environment variables > .env > Default values
Supports two .env files:
- .env in the same directory as the script
- .env in the current working directory
"""
# 1) Prioritize python-dotenv
dotenv_loaded = False
try:
from dotenv import load_dotenv # type: ignore
from pathlib import Path
dotenv_paths = [
Path(__file__).with_name('.env'),
Path.cwd() / '.env'
]
for p in dotenv_paths:
if p.exists():
load_dotenv(dotenv_path=str(p), override=False)
dotenv_loaded = True
logger.info(f"Loaded .env using python-dotenv: {p}")
break
except Exception:
pass
# 2) If not loaded via python-dotenv, manually load
if not dotenv_loaded:
script_env = os.path.join(os.path.dirname(__file__), '.env')
cwd_env = os.path.join(os.getcwd(), '.env')
_manual_load_dotenv([script_env, cwd_env])
# 3) Read environment variables
base_url = os.getenv('TCA_BASE_URL', 'https://tca.tencent.com')
tca_token = os.getenv('TCA_TOKEN', '')
user_id = os.getenv('TCA_USER_ID', '')
org_sid = os.getenv('TCA_ORG_SID', '')
team_name = os.getenv('TCA_TEAM_NAME', '')
repo_url = os.getenv('TCA_REPO_URL', '')
repo_branch = os.getenv('TCA_REPO_BRANCH', '')
repo_mr_branch = os.getenv('TCA_REPO_MR_BRANCH', '')
scm_account_id = os.getenv('TCA_SCM_ACCOUNT_ID', '')
scheme_id = os.getenv('TCA_SCHEME_ID', '')
incr_scan = os.getenv('TCA_INCR_SCAN', False)
ignore_branch_issue = os.getenv('TCA_IGNORE_BRANCH_ISSUE', '')
ignore_merged_issue = os.getenv('TCA_IGNORE_MERGED_ISSUE', False)
return TCAConfig(
base_url=base_url,
tca_token=tca_token,
user_id=user_id,
org_sid=org_sid,
team_name=team_name,
repo_url=repo_url,
scm_account_id=int(scm_account_id),
repo_branch=repo_branch,
repo_mr_branch=repo_mr_branch,
scheme_id=int(scheme_id),
incr_scan=str_to_bool(incr_scan),
ignore_branch_issue=ignore_branch_issue,
ignore_merged_issue=str_to_bool(ignore_merged_issue),
)
def main():
"""Main function - Example usage"""
# Load configuration (priority: environment variables > config.py > default values)
config = load_config_from_env()
logger.info(
f"Loaded configuration: base_url={config.base_url}, "
f"org_sid={'***' if config.org_sid else ''}, "
f"tca_token={'***' if config.tca_token else ''}, "
f"user_id={'***' if config.user_id else ''}, "
f"team_name={config.team_name}, "
f"repo_url={config.repo_url}, "
f"repo_branch={config.repo_branch}, "
f"repo_mr_branch={config.repo_mr_branch}, "
f"scm_account_id={config.scm_account_id}, "
f"scheme_id={config.scheme_id}, "
f"incr_scan={config.incr_scan}, "
f"ignore_branch_issue={config.ignore_branch_issue}, "
f"ignore_merged_issue={config.ignore_merged_issue}"
)
# Validate required configurations
if (not config.org_sid \
or not config.tca_token \
or not config.user_id \
or not config.team_name \
or not config.repo_url \
or not config.repo_branch \
or not config.scm_account_id \
or not config.scheme_id):
logger.error(
"Missing required configurations, please set TCA_USER_ID, TCA_TOKEN, TCA_ORG_SID, TCA_TEAM_NAME, TCA_REPO_URL, TCA_REPO_BRANCH, TCA_SCM_ACCOUNT_ID, TCA_SCHEME_ID")
sys.exit(1)
# Create pipeline instance
pipeline = TCAPipeline(config)
scan_result = pipeline.run_full_analysis()
if scan_result:
logger.info("Pipeline executed successfully")
sys.exit(0)
else:
logger.error("Pipeline execution failed")
sys.exit(1)
if __name__ == "__main__":
main()