
API 触发分析
本文档旨在指引如何通过 TCA API 的形式触发执行分析。TCA开放API支持三种分析触发场景:代码库分析、制品库分析 和 源码包分析,三者的 API 调用流程相似但存在差异。
应用场景
可封装设计成 API 脚本,根据需求调用 API 触发分析。
可封装设计成 CI 插件,集成到 CI 流水线中触发分析。
三种触发场景说明
代码库分析场景:通过 API 将代码库(Git/SVN)登记至 TCA 平台,创建分析项目后触发代码分析。适用于代码质量检测、代码规范审查、代码度量等场景。
制品库分析场景:通过 API 将制品库登记至 TCA 平台,创建分析项目后提交制品文件地址触发二进制成分分析。适用于制品安全审计、开源组件风险检测、敏感信息扫描等场景。
源码包分析场景:通过 API 将源码包登记至 TCA 平台,创建分析项目后提交源码包文件下载地址触发代码分析。适用于无 Git/SVN 托管的代码工程、离线代码包的代码质量检测等场景。
| 对比项 | 代码库分析 | 制品库分析 | 源码包分析 |
|---|---|---|---|
| 分析对象 | Git/SVN 代码仓库 | 二进制制品(Docker、Image、APK 等) | 压缩源码包(.zip/.tar.gz/.tar) |
| 分析能力 | 代码检查、圈复杂度、重复代码、代码统计、源码组件成分等 | 二进制组件成分分析(SCA)、安全审计、敏感信息检测等 | 代码检查、圈复杂度、重复代码、代码统计、源码组件成分等(同代码库) |
| 触发方式 | 支持增量/全量扫描、合并请求触发 | 提供制品文件下载地址触发分析 | 提供源码包文件下载地址触发分析 |
| 前置依赖 | 需要代码库凭证(用于拉取代码) | 无需代码库凭证,需提供制品下载地址 | 无需代码库凭证,需提供源码包文件下载地址 |
| 结果类型 | 代码检查、圈复杂度、重复代码、代码统计、质量门禁 | SCA 概览、安全审计、CheckSec、敏感信息 | 代码检查、圈复杂度、重复代码、代码统计、质量门禁(同代码库) |
前置步骤
前置步骤总览
获取 API 访问令牌:API 接口鉴权所需,
user_id、token。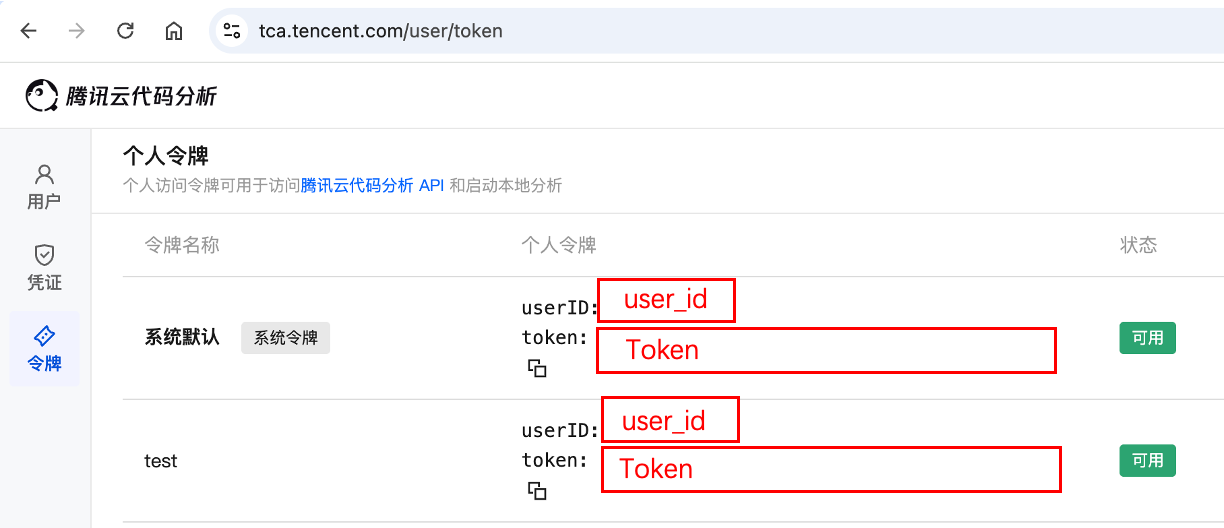
获取团队标识 org_sid:进入团队列表页面,点击目标团队进入详情页,从 URL 链接中获取团队标识
org_sid。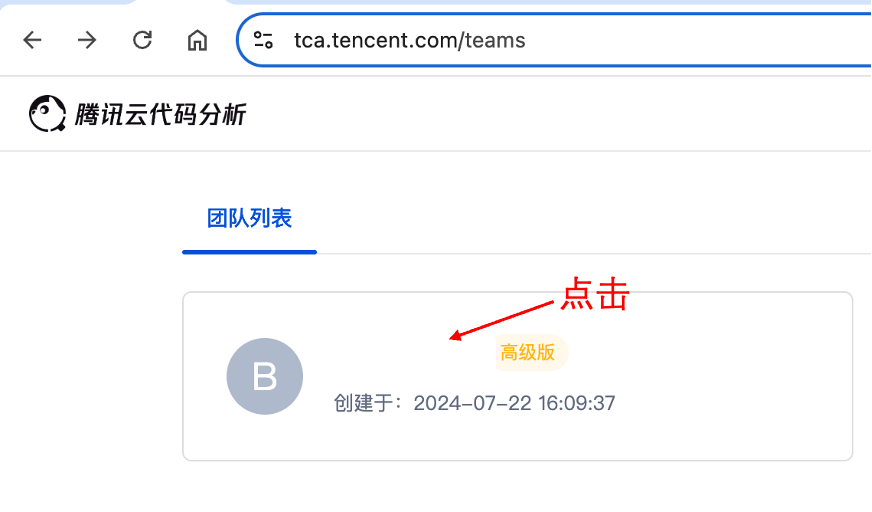
获取代码库凭证 ID:登记代码库所需,用于执行分析时拉取代码。进入凭证管理页面获取
scm_account_id,如不存在则需先创建凭证。制品库分析场景和源码包分析场景无需此步骤。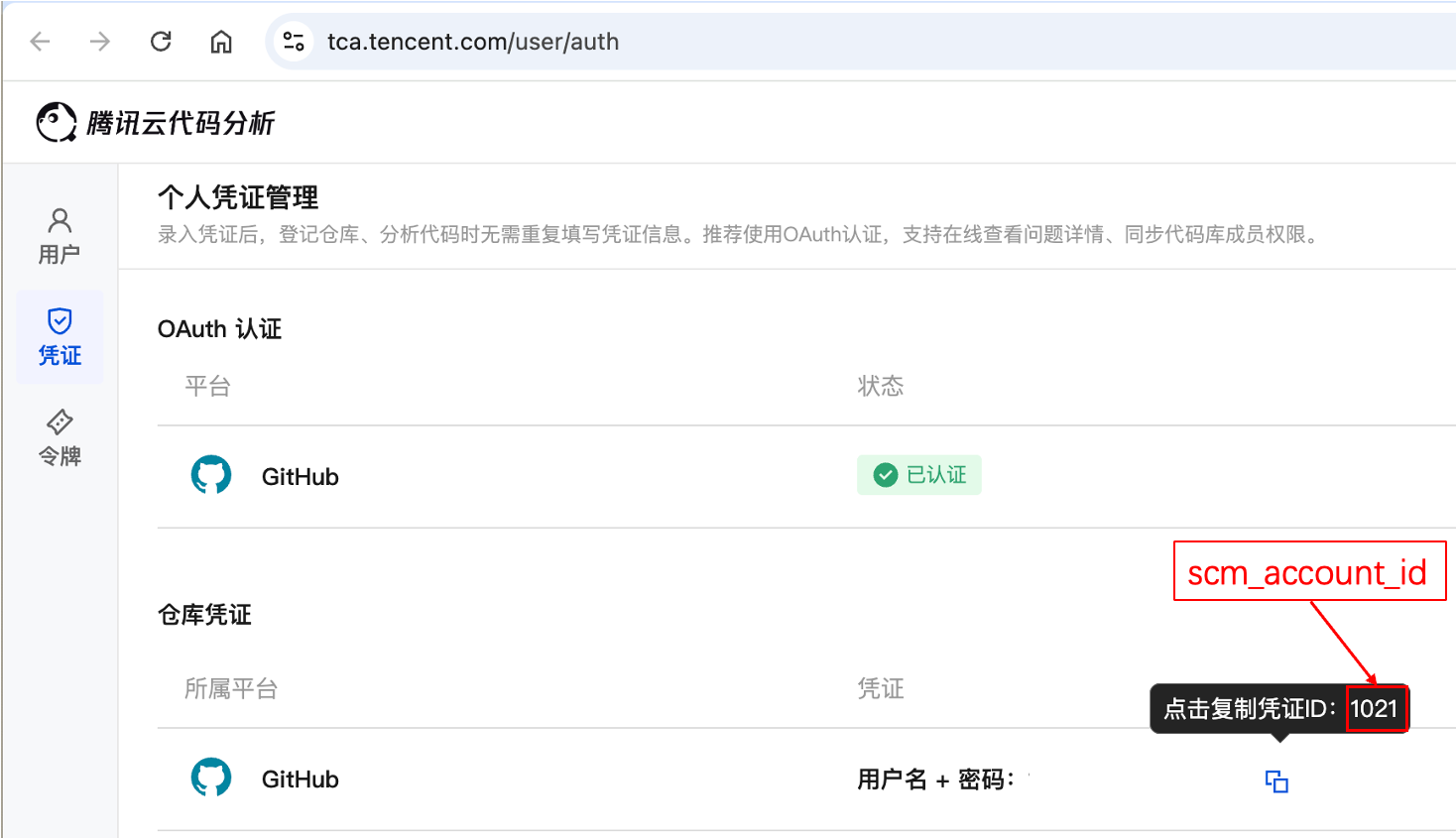
获取分析方案 ID:创建分析项目所需。进入分析方案的基础配置页面,或从 URL 链接中获取
scheme_id,如不存在则根据需要创建团队/项目分析方案。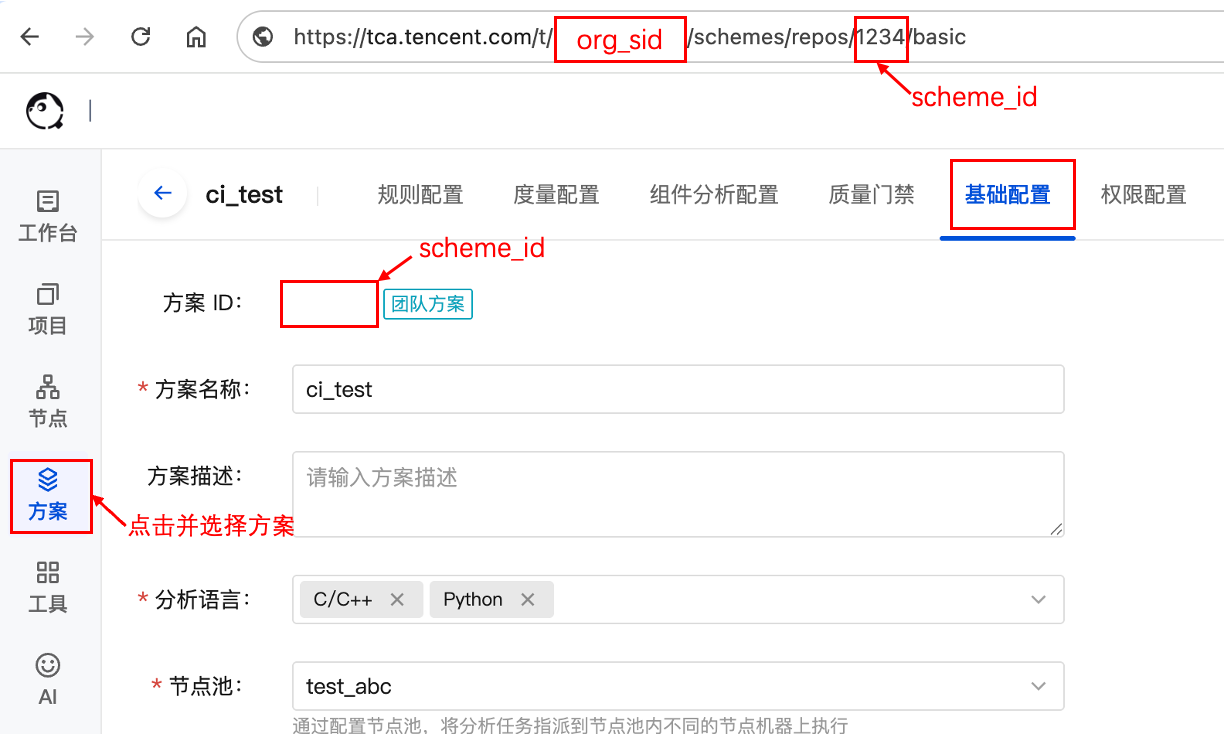
接入在线节点:执行分析所需。API 触发的分析任务在 TCA 线上节点执行,需确保存在可用的在线节点,否则分析将因无可用节点而失败。
API 接口鉴权参见文档:API 接口鉴权
鉴权头部生成(需要前置步骤中获取的user_id和token)
from time import time
from hashlib import sha256
def get_headers(user_id, token):
timestamp = int(time())
token_sig = "%s%s#%s#%s%s" % (timestamp, user_id, token, user_id, timestamp)
ticket = sha256(token_sig.encode("utf-8")).hexdigest().upper()
return {
"TCA-USERID": user_id,
"TCA-TIMESTAMP": str(timestamp),
"TCA-TICKET": ticket
}
场景一:代码库分析
通过调用 API 的形式,将代码库登记至 TCA 平台内,并基于分析方案等配置创建分析项目,随后触发代码分析。由 TCA 调度任务到节点机器上执行代码分析,通过轮询的方式获取分析任务结果。最终根据结果中的门禁信息判断门禁是否通过,并获取任务执行的详细信息以及问题列表等信息。
层级说明
团队 -> 项目 -> 代码库 -> 分析项目(分支 + 分析路径 + 分析方案组成唯一分析项目)。
1. 创建项目
建议先获取是否存在项目,如果不存在,则创建项目,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/" post_data = { "name": "team_name", # 项目名称,需自行填写,例如:ci_team "display_name": "team_name" # 项目展示名称,需自行填写,例如:ci_team } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
2. 登记代码库
建议先通过获取代码库接口确认代码库是否存在,如果不存在,则创建登记代码库,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/" post_data = { "scm_url": "repo_url", # 代码库地址,需自行填写,例如:https://github.com/xxx/xxx.git "scm_type": "git", "scm_auth": { "auth_type": "password", "scm_account": scm_account_id # 代码库凭证 ID,需自行填写(在前置步骤中获取),例如:123 }, "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
3. 创建分析项目
建议先通过获取分析项目接口确定是否存在对应分析项目,如果不存在,则创建分析项目,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/" post_data = { "branch": "repo_branch", # 分支名,需自行填写,例如:master "global_scheme_id": scheme_id, # 分析方案 ID,需自行填写(在前置步骤中获取),例如:123 "use_scheme_template": True, "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
4. 启动分析任务
POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scans/create/
普通触发
post_data = { "incr_scan": True, # 是否增量扫描 False是全量, True是增量 }合并请求触发
post_data = { "incr_scan": True, # 是否增量扫描 False是全量, True是增量 "ignore_branch_issue": "target_branch", # 过滤的分支名称,过滤参考分支名引入的问题,需自行填写,例如:master,为""或不填,则为普通触发 }
import requests
url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scans/create/"
headers = get_headers(user_id, token)
resp = requests.post(url, json=post_data, headers=headers)
result = resp.json()
print(result)
5. 轮询任务状态
GET /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/
获取任务详情 API:持续轮询直到 state == 2。常见返回:
result_code == 0:扫描完成,结果可用。result_code == 1:代码库未做修改,触发的增量扫描,结果可用。result_code == 2:扫描结果重定向,从result_msg中获取新的job_id,继续轮询,直至state == 2且result_code == 0,结果可用。result_code > 100:扫描完成,分析失败,结果不可用。
可参考脚本中wait_for_scan_completion方法。
6. 获取分析结果
根据任务分析结果码result_code不同,获取扫描概览的方式也不同。
6.1. 全量扫描或代码有修改的增量扫描(result_code == 0、result_code == 2)
6.1.1. 获取完整结果
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
results = result.get("data", {}).get("results", [])
print(result[0])
6.1.2. 代码检查结果(lintscan)
lint = result[0].get("lintscan", {})
total = lint.get("total", {})
print({
"active": total.get("state_detail", {}).get("active"), # 未处理问题数
"fatal_active": total.get("severity_detail", {}).get("fatal", {}).get("active"), # 严重问题数
"error_active": total.get("severity_detail", {}).get("error", {}).get("active"), # 错误问题数
"warning_active": total.get("severity_detail", {}).get("warning", {}).get("active"), # 警告问题数
"info_active": total.get("severity_detail", {}).get("info", {}).get("active"), # 提示问题数
"issue_detail_num": lint.get("issue_detail_num"), # 问题总数(未聚合)
"issue_open_num": lint.get("issue_open_num"), # 新增缺陷数
"issue_fix_num": lint.get("issue_fix_num"), # 修复缺陷数
})
6.1.3. 圈复杂度结果(cyclomaticcomplexityscan)
cc = result[0].get("cyclomaticcomplexityscan", {})
custom_summary = cc.get("custom_summary", {})
print({
"over_cc_func_count": custom_summary.get("over_cc_func_count"), # 该分支所有超标方法个数
"over_cc_func_average": custom_summary.get("over_cc_func_average"), # 该分支所有超标方法平均复杂度
"min_ccn": cc.get("min_ccn"), # 圈复杂度标准(超标阈值)
})
6.1.4. 重复代码结果(duplicatescan)
dup = result[0].get("duplicatescan", {})
print({
"duplicate_block_count": dup.get("duplicate_block_count"), # 重复块数
"total_duplicate_line_count": dup.get("total_duplicate_line_count"), # 重复行数
"duplicate_file_count": dup.get("duplicate_file_count"), # 重复文件数(新增字段)
})
6.1.5. 代码统计结果(clocscan)
cloc = result[0].get("clocscan", {})
print({
"code_line_num": cloc.get("code_line_num"), # 代码行数
"comment_line_num": cloc.get("comment_line_num"), # 注释行数
"blank_line_num": cloc.get("blank_line_num"), # 空白行数
"total_line_num": cloc.get("total_line_num"), # 总行数
})
6.1.6. 获取质量门禁状态(Quality Gate)
quality = result[0].get("qualityscan", {})
status = quality.get("status") # "success": 门禁通过,"failure": 门禁未通过, "close": 门禁未开启
description = quality.get("description")
if status == "success":
print("质量门禁通过")
elif status == "close":
print("质量门禁未开启")
else:
print(f"质量门禁未通过:{description}")
6.2. 代码无修改的增量扫描(result_code == 1)
6.2.1. 获取扫描概览
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
results = result.get("data", {})
print(results)
- 代码检查结果:
results["lintscan"] - 圈复杂度结果:
results["cyclomaticcomplexityscan"] - 重复代码结果:
results["duplicatescan"] - 代码统计结果:
results["clocscan"]
6.2.2. 获取质量门禁结果
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/latestscan/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/latestscan/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
results = result.get("data", {})
quality = results.get("qualityscan", {})
status = quality.get("status") # "success": 门禁通过,"failure": 门禁未通过, "close": 门禁未开启
description = quality.get("description")
if status == "success":
print("质量门禁通过")
elif status == "close":
print("质量门禁未开启")
else:
print(f"质量门禁未通过:{description}")
6.3. 各维度扫描历史结果接口
可通过以下独立接口获取各维度最新一次扫描结果。
6.3.1. 代码扫描历史结果列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/lintscans/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/lintscans/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
lint_data = result.get("data", {}).get("results", [{}])[0]
total = lint_data.get("total", {})
print({
"active": total.get("state_detail", {}).get("active"), # 未处理问题数
"fatal_active": total.get("severity_detail", {}).get("fatal", {}).get("active"), # 严重问题数
"error_active": total.get("severity_detail", {}).get("error", {}).get("active"), # 错误问题数
"warning_active": total.get("severity_detail", {}).get("warning", {}).get("active"), # 警告问题数
"info_active": total.get("severity_detail", {}).get("info", {}).get("active"), # 提示问题数
"issue_detail_num": lint_data.get("issue_detail_num"), # 问题总数(未聚合)
"issue_open_num": lint_data.get("issue_open_num"), # 新增缺陷数
"issue_fix_num": lint_data.get("issue_fix_num"), # 修复缺陷数
})
6.3.2. 圈复杂度扫描历史结果列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/cycscans/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/cycscans/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
cyc_data = result.get("data", {}).get("results", [{}])[0]
custom_summary = cyc_data.get("custom_summary", {})
print({
"over_cc_func_count": custom_summary.get("over_cc_func_count"), # 该分支所有超标方法个数
"over_cc_func_average": custom_summary.get("over_cc_func_average"), # 该分支所有超标方法平均复杂度
"min_ccn": custom_summary.get("min_ccn") or cyc_data.get("min_ccn"), # 圈复杂度标准(超标阈值)
"scan_revision": cyc_data.get("scan_revision"), # 对应的代码版本(commit)
})
6.3.3. 重复代码扫描历史结果列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/dupscans/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/dupscans/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
dup_data = result.get("data", {}).get("results", [{}])[0]
print({
"duplicate_block_count": dup_data.get("duplicate_block_count"), # 重复块数
"total_duplicate_line_count": dup_data.get("total_duplicate_line_count"), # 重复行数
"duplicate_file_count": dup_data.get("duplicate_file_count"), # 重复文件数
"scan_revision": dup_data.get("scan_revision"), # 对应的代码版本(commit)
})
6.3.4. 代码统计扫描历史结果列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/clocscans/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/clocscans/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
cloc_data = result.get("data", {}).get("results", [{}])[0]
print({
"code_line_num": cloc_data.get("code_line_num"), # 代码行数
"comment_line_num": cloc_data.get("comment_line_num"), # 注释行数
"blank_line_num": cloc_data.get("blank_line_num"), # 空白行数
"total_line_num": cloc_data.get("total_line_num"), # 总行数
"scan_revision": cloc_data.get("scan_revision"), # 对应的代码版本(commit)
})
6.3.5. SCA 扫描历史结果列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
sca_data = result.get("data", {}).get("results", [{}])[0]
meta_data = sca_data.get("meta_data") or {}
def risk_count(data_list, risk_key):
"""从 [{risk: ..., count: ...}, ...] 列表中提取指定 risk 的 count"""
for item in (data_list or []):
if isinstance(item, dict) and item.get("risk") == risk_key:
return item.get("count", 0)
return 0
malware_data = sca_data.get("malware_data")
copyright_data = sca_data.get("copyright_tampering_data")
license_tampering_data = sca_data.get("license_tampering_data")
base_audit_data = sca_data.get("base_audit_data")
cve_data = sca_data.get("cve_data")
license_data = sca_data.get("license_data")
source_reuse_rate = meta_data.get("source_reuse_rate") or 0
print({
"file_num": sca_data.get("file_num"), # 文件总数
"self_rate": round((1 - source_reuse_rate) * 100, 2), # 自研率(%)
"source_reuse_rate": round(source_reuse_rate * 100, 2), # 开源代码占比(%)
# 病毒检测
"malware_count": risk_count(malware_data, "Malware"), # 病毒数
"malware_pass_count": risk_count(malware_data, "Pass"), # 非病毒数
# Copyright 检测(copyright_tampering_data)
"copyright_has": risk_count(copyright_data, "Has"), # 声明 Copyright
"copyright_without": risk_count(copyright_data, "Without"), # 未声明 Copyright
"copyright_modified": risk_count(copyright_data, "Modified"), # Copyright 篡改
# License 篡改检测(license_tampering_data)
"license_has": risk_count(license_tampering_data, "Has"), # 声明 License
"license_without": risk_count(license_tampering_data, "Without"), # 未声明 License
"license_modified": risk_count(license_tampering_data, "Modified"), # License 篡改
# 安全审计(base_audit_data)
"audit_high": risk_count(base_audit_data, "High"), # 安全审计-高危
"audit_medium": risk_count(base_audit_data, "Medium"), # 安全审计-中危
"audit_warning": risk_count(base_audit_data, "Warning"), # 安全审计-警告
"audit_pass": risk_count(base_audit_data, "Pass"), # 安全审计-通过
"audit_na": risk_count(base_audit_data, "N/A"), # 安全审计-N/A
# 漏洞审计(cve_data)
"cve_critical": risk_count(cve_data, "Critical"), # 漏洞审计-严重
"cve_high": risk_count(cve_data, "High"), # 漏洞审计-高危
"cve_medium": risk_count(cve_data, "Medium"), # 漏洞审计-中危
"cve_low": risk_count(cve_data, "Low"), # 漏洞审计-低危
"cve_na": risk_count(cve_data, "NotAvailable"), # 漏洞审计-N/A
# License 审计(license_data)
"license_high": risk_count(license_data, "High"), # License 审计-高风险
"license_middle": risk_count(license_data, "Middle"), # License 审计-中风险
"license_low": risk_count(license_data, "Low"), # License 审计-低风险
"license_na": risk_count(license_data, "NotAvailable"), # License 审计-N/A
})
7. 获取代码检查问题数据
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/
import requests
import json
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
print(json.dumps(result, indent=2, ensure_ascii=False))
场景二:制品库分析
通过调用 API 的形式,将制品库登记至 TCA 平台内,并基于分析方案等配置创建制品库分析项目,随后提交制品文件地址触发二进制成分分析(SCA)。由 TCA 调度任务到节点机器上执行分析,通过轮询的方式获取分析任务结果。最终获取 SCA 分析结果,包括安全审计、CheckSec、敏感信息等。
层级说明
团队 -> 项目 -> 制品库 -> 分析项目(制品库名称 + 分析方案组成唯一分析项目)。
1. 创建项目
建议先获取是否存在项目,如果不存在,则创建项目,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/" post_data = { "name": "team_name", # 项目名称,需自行填写,例如:ci_team "display_name": "team_name" # 项目展示名称,需自行填写,例如:ci_team } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
2. 登记制品库
建议先通过获取制品库接口确认制品库是否存在,如果不存在,则创建登记制品库,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/" post_data = { "name": "artifact_name", # 制品库名称,需自行填写,例如:my_artifact "artifact_type": "binary", # 制品类型,可选值:binary、docker、RTOS 等 "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
3. 创建分析项目
建议先获取是否存在对应制品库分析项目,如果不存在,则创建分析项目,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/" post_data = { "name": "artifact_project_name", # 制品库分析项目名称,需自行填写,例如:my_artifact_project "global_scheme_id": scheme_id, # 分析方案 ID,需自行填写(在前置步骤中获取),例如:123 "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
4. 启动分析任务
POST /server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/{project_id}/scans/
import requests
url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/{project_id}/scans/"
headers = get_headers(user_id, token)
post_data = {
"artifact_url": "artifact_url", # 制品文件的下载地址,需自行填写,例如:https://example.com/path/to/artifact.zip
"created_from": "api"
}
resp = requests.post(url, json=post_data, headers=headers)
result = resp.json()
print(result)
5. 轮询任务状态
GET /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/
获取制品库任务详情 API:持续轮询直到 state == 2。常见返回:
result_code == 0:扫描完成,结果可用。result_code > 100:扫描完成,分析失败,结果不可用。
import requests
url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
print(result)
6. 获取分析结果
SCA 相关接口较为丰富,便于开发者灵活获取所需数据。以下列举了常用接口,如需了解更多,可访问 API 文档 自行查阅。
获取 SCA 概览列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/
获取安全审计 SCA 概览列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/{scans_id}/auditchecks/
获取制品项目 CheckSec 列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/{scans_id}/checksecs/
获取制品项目敏感信息列表
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/{scans_id}/sensitives/
以上接口的请求方式如下:
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
print(result)
6.1. SCA 概览结果字段说明
SCA 概览列表接口(sca/scans/)返回的 data.results 列表中,每条记录的常用字段如下:
sca_data = result.get("data", {}).get("results", [{}])[0]
meta_data = sca_data.get("meta_data") or {}
def risk_count(data_list, risk_key):
"""从 [{risk: ..., count: ...}, ...] 列表中提取指定 risk 的 count"""
for item in (data_list or []):
if isinstance(item, dict) and item.get("risk") == risk_key:
return item.get("count", 0)
return 0
malware_data = sca_data.get("malware_data")
base_audit_data = sca_data.get("base_audit_data")
cve_data = sca_data.get("cve_data")
license_data = sca_data.get("license_data")
source_reuse_rate = meta_data.get("source_reuse_rate") or 0
print({
"file_num": sca_data.get("file_num"), # 文件总数
"source_reuse_rate": round(source_reuse_rate * 100, 2), # 源码复用率(%)
"self_rate": round((1 - source_reuse_rate) * 100, 2), # 自研率(%)
# 病毒检测
"malware_count": risk_count(malware_data, "Malware"), # 病毒数
"malware_pass_count": risk_count(malware_data, "Pass"), # 非病毒数
# 安全审计(base_audit_data)
"audit_high": risk_count(base_audit_data, "High"), # 安全审计-高危
"audit_medium": risk_count(base_audit_data, "Medium"), # 安全审计-中危
"audit_warning": risk_count(base_audit_data, "Warning"), # 安全审计-警告
"audit_pass": risk_count(base_audit_data, "Pass"), # 安全审计-通过
"audit_na": risk_count(base_audit_data, "N/A"), # 安全审计-N/A
# 漏洞审计(cve_data)
"cve_critical": risk_count(cve_data, "Critical"), # 漏洞审计-严重
"cve_high": risk_count(cve_data, "High"), # 漏洞审计-高危
"cve_medium": risk_count(cve_data, "Medium"), # 漏洞审计-中危
"cve_low": risk_count(cve_data, "Low"), # 漏洞审计-低危
"cve_na": risk_count(cve_data, "NotAvailable"), # 漏洞审计-N/A
# License 审计(license_data)
"license_high": risk_count(license_data, "High"), # License 审计-高风险
"license_middle": risk_count(license_data, "Middle"), # License 审计-中风险
"license_low": risk_count(license_data, "Low"), # License 审计-低风险
"license_na": risk_count(license_data, "NotAvailable"), # License 审计-N/A
})
场景三:源码包分析
通过调用 API 的形式,将源码包登记至 TCA 平台内,并基于分析方案等配置创建源码包分析项目,随后提交源码包文件下载地址触发代码分析。由 TCA 调度任务到节点机器上执行分析,通过轮询的方式获取分析任务结果。最终获取代码分析结果,包括代码检查、圈复杂度、重复代码、代码统计等。
层级说明
团队 -> 项目 -> 源码包(代码库形式登记) -> 分析项目(源码包版本 + 分析方案组成唯一分析项目)。
说明
源码包是代码库的一种特殊形式(scm_type 为 package),登记和创建分析项目使用代码库接口(repos/),启动分析使用制品库的扫描接口(artifact/repos/.../scans/),分析结果的获取与代码库分析一致。源码包适用于无 Git/SVN 托管的代码工程,将代码压缩为 .zip/.tar.gz/.tar 格式后提供下载地址即可触发代码分析。
1. 创建项目
建议先获取是否存在项目,如果不存在,则创建项目,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/" post_data = { "name": "team_name", # 项目名称,需自行填写,例如:ci_team "display_name": "team_name" # 项目展示名称,需自行填写,例如:ci_team } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
2. 登记源码包
建议先通过获取源码包接口确认源码包是否存在,如果不存在,则创建登记源码包,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/" post_data = { "scm_url": "source_pkg_name", # 源码包名称,需自行填写,例如:my_source_package "scm_type": "package", # 类型固定为 package(源码包) "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
3. 创建分析项目
建议先获取是否存在对应源码包分析项目,如果不存在,则创建分析项目,如果存在,则直接使用。
GET|POST /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/
import requests url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/" post_data = { "branch": "source_pkg_project_name", # 源码包分析项目名称(作为版本标识),需自行填写,例如:my_source_pkg_v1 "global_scheme_id": scheme_id, # 分析方案 ID,需自行填写(在前置步骤中获取),例如:123 "created_from": "api" } headers = get_headers(user_id, token) resp = requests.post(url, json=post_data, headers=headers) result = resp.json() print(result)
4. 启动分析任务
POST /server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/{project_id}/scans/
import requests
url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/{project_id}/scans/"
headers = get_headers(user_id, token)
post_data = {
"artifact_url": "source_pkg_url", # 源码包文件的下载地址,需自行填写,例如:https://example.com/path/to/source.zip
"created_from": "api"
}
resp = requests.post(url, json=post_data, headers=headers)
result = resp.json()
print(result)
5. 轮询任务状态
GET /server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/
获取源码包任务详情 API:持续轮询直到 state == 2。常见返回:
result_code == 0:扫描完成,结果可用。result_code > 100:扫描完成,分析失败,结果不可用。
import requests
url = f"{base_url}/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
print(result)
6. 获取分析结果
源码包分析扫描完成后(result_code == 0),可通过以下接口获取分析结果。
6.1. 获取完整结果
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/
import requests
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
results = result.get("data", {}).get("results", [])
print(results[0])
6.2. 代码检查结果(lintscan)
lint = results[0].get("lintscan", {})
total = lint.get("total", {})
print({
"active": total.get("state_detail", {}).get("active"), # 未处理问题数
"fatal_active": total.get("severity_detail", {}).get("fatal", {}).get("active"), # 严重问题数
"error_active": total.get("severity_detail", {}).get("error", {}).get("active"), # 错误问题数
"warning_active": total.get("severity_detail", {}).get("warning", {}).get("active"), # 警告问题数
"info_active": total.get("severity_detail", {}).get("info", {}).get("active"), # 提示问题数
"issue_detail_num": lint.get("issue_detail_num"), # 问题总数(未聚合)
"issue_open_num": lint.get("issue_open_num"), # 新增缺陷数
"issue_fix_num": lint.get("issue_fix_num"), # 修复缺陷数
})
6.3. 圈复杂度结果(cyclomaticcomplexityscan)
cc = results[0].get("cyclomaticcomplexityscan", {})
custom_summary = cc.get("custom_summary", {})
print({
"over_cc_func_count": custom_summary.get("over_cc_func_count"), # 该分支所有超标方法个数
"over_cc_func_average": custom_summary.get("over_cc_func_average"), # 该分支所有超标方法平均复杂度
"min_ccn": cc.get("min_ccn"), # 圈复杂度标准(超标阈值)
})
6.4. 重复代码结果(duplicatescan)
dup = results[0].get("duplicatescan", {})
print({
"duplicate_block_count": dup.get("duplicate_block_count"), # 重复块数
"total_duplicate_line_count": dup.get("total_duplicate_line_count"), # 重复行数
"duplicate_file_count": dup.get("duplicate_file_count"), # 重复文件数
})
6.5. 代码统计结果(clocscan)
cloc = results[0].get("clocscan", {})
print({
"code_line_num": cloc.get("code_line_num"), # 代码行数
"comment_line_num": cloc.get("comment_line_num"), # 注释行数
"blank_line_num": cloc.get("blank_line_num"), # 空白行数
"total_line_num": cloc.get("total_line_num"), # 总行数
})
6.6. 获取质量门禁状态(Quality Gate)
quality = results[0].get("qualityscan", {})
status = quality.get("status") # "success": 门禁通过,"failure": 门禁未通过, "close": 门禁未开启
description = quality.get("description")
if status == "success":
print("质量门禁通过")
elif status == "close":
print("质量门禁未开启")
else:
print(f"质量门禁未通过:{description}")
7. 获取代码检查问题数据
GET /server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/
import requests
import json
url = f"{base_url}/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/"
headers = get_headers(user_id, token)
resp = requests.get(url, headers=headers)
result = resp.json()
print(json.dumps(result, indent=2, ensure_ascii=False))
脚本参考
代码库分析脚本
环境变量
执行脚本时,可以注入环境变量,动态调整参数,实现自动化集成。
# TCA 平台服务地址
TCA_BASE_URL=https://tca.tencent.com
# API 访问令牌
TCA_USER_ID=your_user_id
TCA_TOKEN=your_token
# 团队唯一标识
TCA_ORG_SID=your_org_sid
# 项目唯一标识
TCA_TEAM_NAME=your_team_name
# 代码库 URL
TCA_REPO_URL=your_repo_url
# 代码库凭证 ID
TCA_SCM_ACCOUNT_ID=your_scm_account_id
# 分析方案 ID,可使用团队/项目分析方案,注意权限问题
TCA_SCHEME_ID=your_scheme_id
# 分支名称
TCA_REPO_BRANCH=your_repo_branch
# 是否增量扫描
TCA_INCR_SCAN=true
# 是否忽略已有扫描任务强制启动
TCA_FORCE_CREATE=false
# 合并请求场景下的过滤的分支名称,会过滤参考分支名引入的问题,需自行填写,例如:master,为""或不填,则为普通触发
TCA_IGNORE_BRANCH_ISSUE=your_ignore_branch
# 扫描最大等待时间(秒),默认600秒(10分钟)
TCA_MAX_WAIT_TIME=600
脚本内容
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
通过 API 启动代码库分析
"""
import os
import sys
import json
import requests
import logging
from typing import Dict, List, Optional, Any, Tuple
from dataclasses import dataclass
from time import time, sleep
from hashlib import sha256
# 日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout),
logging.FileHandler('tca_ci_git_saas.log')
]
)
logger = logging.getLogger(__name__)
# 开放API路径映射
TCA_OPEN_APIS = {
"project_team_list": "%s/server/main/api/orgs/{org_sid}/teams/",
"pt_repo_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/",
"project_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/",
"project_scan_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scans/create/",
"job_detail": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/",
"project_analysis_scan_list": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/",
"project_issue_list": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/",
"project_overview": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/",
"project_overview_latest_scan": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/latestscan/",
"project_sca_scans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/",
"overview_cycscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/cycscans/",
"overview_clocscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/clocscans/",
"overview_dupscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/dupscans/",
"overview_lintscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/lintscans/",
}
@dataclass
class TCAConfig:
"""TCA配置类"""
base_url: str
tca_token: str
user_id: str
org_sid: str
team_name: str
repo_url: str
repo_branch: str
repo_mr_branch: str
scm_account_id: int
scheme_id: int
incr_scan: bool
force_create: bool
ignore_branch_issue: str
timeout: int = 30
max_retries: int = 3
max_wait_time: int = 600
class TCAIntegrationError(Exception):
"""TCA集成异常"""
pass
class TCAClient:
"""TCA API客户端"""
def __init__(self, config: TCAConfig):
self.config = config
self.session = requests.Session()
self._repo_id: Optional[int] = None
self._project_id: Optional[int] = None
def get_headers(self, user_id: Optional[str] = None, token: Optional[str] = None):
timestamp = int(time())
user_id = user_id or self.config.user_id
token = token or self.config.tca_token
token_sig = "%s%s#%s#%s%s" % (timestamp, user_id, token, user_id, timestamp)
ticket = sha256(token_sig.encode("utf-8")).hexdigest().upper()
return {
"TCA-USERID": user_id,
"TCA-TIMESTAMP": str(timestamp),
"TCA-TICKET": ticket
}
def _is_success_status(self, status_code: int) -> bool:
"""判断HTTP状态码是否表示成功(2xx)"""
return 200 <= status_code < 300
def _make_request(self, method: str, url: str, data: Optional[Dict] = None,
params: Optional[Dict] = None) -> Dict:
"""发送API请求,url需为完整路径"""
for attempt in range(self.config.max_retries):
try:
headers = self.get_headers()
response = self.session.request(
method=method,
url=url,
headers=headers,
json=data,
params=params,
timeout=self.config.timeout
)
if self._is_success_status(response.status_code):
return response.json()
elif response.status_code == 401:
raise TCAIntegrationError("TCA Token无效或已过期")
elif response.status_code == 403:
raise TCAIntegrationError("权限不足,请检查团队ID和权限设置")
elif response.status_code == 404:
raise TCAIntegrationError("请求的资源不存在")
elif response.status_code >= 500:
logger.warning(f"服务器错误,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("服务器内部错误,请稍后重试")
sleep(2 ** attempt) # 指数退避
else:
raise TCAIntegrationError(f"API请求失败: {response.status_code} - {response.text}")
except requests.exceptions.Timeout:
logger.warning(f"请求超时,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("请求超时,请检查网络连接")
except requests.exceptions.ConnectionError:
logger.warning(f"连接错误,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("网络连接错误,请检查网络设置")
def _build_url(self, key: str, **kwargs: Any) -> str:
base = self.config.base_url.rstrip('/')
tpl = TCA_OPEN_APIS[key] % base
return tpl.format(**kwargs)
def get_project_teams(self) -> Dict:
url = self._build_url("project_team_list", org_sid=self.config.org_sid)
return self._make_request("GET", url)
def get_pt_repos(self) -> Dict:
url = self._build_url("pt_repo_list", org_sid=self.config.org_sid, team_name=self.config.team_name)
return self._make_request("GET", url)
def get_pt_repo_id(self, repo_url: Optional[str] = None) -> int:
"""根据仓库地址获取团队下对应仓库的ID(仅精确匹配)。
精确比较 `scm_url`,找不到则抛出 TCAIntegrationError。
首次获取后缓存,后续调用直接返回缓存值。
"""
if self._repo_id is not None:
return self._repo_id
result = self.get_pt_repos()
data = result.get("data") or {}
results = data.get("results") or []
repo_url = repo_url or self.config.repo_url
if not isinstance(results, list):
raise TCAIntegrationError("获取团队仓库列表失败,返回格式不正确")
for item in results:
if not isinstance(item, dict):
continue
if repo_url == item.get("scm_url") or repo_url == item.get("format_url"):
repo_id_val = item.get("id")
if repo_id_val is not None:
self._repo_id = int(repo_id_val)
return self._repo_id
raise TCAIntegrationError(f"未在项目 {self.config.team_name} 下找到仓库: {repo_url}")
def create_project_team(self) -> Dict:
"""创建项目"""
logger.info(f"创建项目: {self.config.team_name}")
url = self._build_url("project_team_list", org_sid=self.config.org_sid)
post_data = {
'name': self.config.team_name,
'display_name': self.config.team_name
}
result = self._make_request("POST", url, data=post_data)
return result
def register_pt_repo(self) -> Dict:
"""登记代码库(项目维度)"""
logger.info(f"项目: {self.config.team_name}, 创建代码库: {self.config.repo_url}")
url = self._build_url("pt_repo_list", org_sid=self.config.org_sid, team_name=self.config.team_name)
post_data = {
'scm_url': self.config.repo_url,
'scm_type': "git",
'scm_auth': {
"auth_type": "password",
"scm_account": self.config.scm_account_id
},
'created_from': "api"
}
result = self._make_request("POST", url, data=post_data)
return result
def create_project(self) -> Dict:
"""创建分析项目"""
logger.info(f"项目: {self.config.team_name}, 创建代码库: {self.config.repo_url}的分析项目")
repo_id = self.get_pt_repo_id(self.config.repo_url)
url = self._build_url("project_list", org_sid=self.config.org_sid, team_name=self.config.team_name,
repo_id=repo_id)
post_data = {
'branch': self.config.repo_branch,
'global_scheme_id': self.config.scheme_id,
'use_scheme_template': True,
'created_from': "api"
}
result = self._make_request("POST", url, data=post_data)
return result
def get_projects(self) -> Dict:
repo_id = self.get_pt_repo_id(self.config.repo_url)
url = self._build_url("project_list", org_sid=self.config.org_sid, team_name=self.config.team_name,
repo_id=repo_id)
return self._make_request("GET", url)
def get_project_id(self, scheme_id: Optional[int] = None, branch: Optional[str] = None) -> int:
"""根据 scan_scheme.id 和 branch 获取分析项目ID。
- 从项目列表中精确匹配 `scan_scheme.id` 与 `branch`
首次获取后缓存,后续调用直接返回缓存值。
"""
if self._project_id is not None:
return self._project_id
scheme_id = scheme_id or self.config.scheme_id
branch = branch or self.config.repo_branch
logger.info(f"scheme_id={scheme_id}, branch={branch}")
result = self.get_projects()
data = result.get("data") or {}
results = data.get("results") or []
if not isinstance(results, list):
raise TCAIntegrationError("获取项目列表失败,返回格式不正确")
for item in results:
if not isinstance(item, dict):
continue
item_scheme = (item.get("scan_scheme") or {}).get("id")
item_branch = item.get("branch")
if int(item_scheme) == int(scheme_id) and item_branch == branch:
proj_id = item.get("id")
if proj_id is not None:
self._project_id = int(proj_id)
return self._project_id
raise TCAIntegrationError(f"未找到匹配的分析项目,scheme_id={scheme_id}, branch={branch}")
def start_scan(self) -> Dict:
"""启动扫描任务"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_scan_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
incr_scan = self.config.incr_scan
force_create = self.config.force_create
ignore_branch_issue = self.config.ignore_branch_issue
post_data = {
'incr_scan': incr_scan,
'force_create': force_create,
'ignore_branch_issue': ignore_branch_issue
}
result = self._make_request("POST", url, data=post_data)
logger.info(f"启动扫描任务结果: {result}")
return result
def wait_for_scan_completion(self, job_id: int) -> Dict:
"""等待分析任务状态变为 2(已完成),并处理重定向 job_id"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("job_detail", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id, job_id=job_id)
max_wait_time = self.config.max_wait_time
interval = 30 # 每隔 30秒请求一次
start_time = int(time())
while True:
results = self._make_request("GET", url)
data = results.get("data", {}) or {}
state = data.get("state")
result_code = data.get("result_code")
if state == 2:
if result_code == 0 or result_code == 1:
logging.info("扫描结果已出,结束等待")
break
if result_code == 2:
result_msg_raw = data.get("result_msg") or {}
if isinstance(result_msg_raw, str):
try:
result_msg = json.loads(result_msg_raw)
except Exception as e:
raise TCAIntegrationError(f"扫描结果重定向但 result_msg 无法解析: {result_msg_raw}")
else:
result_msg = result_msg_raw
new_job_id = result_msg.get("job_id") if isinstance(result_msg, dict) else None
if not new_job_id:
raise TCAIntegrationError("扫描结果重定向但未返回新的 job_id")
job_id = int(new_job_id)
url = self._build_url("job_detail", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id, job_id=job_id)
logging.info(f"扫描结果重定向,使用新的 job_id={job_id} 继续轮询")
else:
raise TCAIntegrationError(f"扫描失败: result_code={result_code}, result_msg={data.get('result_msg')}")
elapsed = int(time()) - start_time
if elapsed > max_wait_time:
logger.info(f"扫描超过{max_wait_time}秒,扫描状态仍未改变,扫描失败")
raise TCAIntegrationError(f"扫描超过{max_wait_time}秒,扫描状态仍未改变,扫描失败")
logging.info(
f"代码正在扫描中(当前 state: {state if state is not None else '无数据'}),等待{interval}秒后重试...")
sleep(interval)
return results
def get_scan_info(self, job_id: int) -> Dict:
"""获取指定 job_id 的分析结果信息"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_analysis_scan_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
response = self._make_request("GET", url, params={"id": job_id})
results = response.get("data", {}).get("results", [])
if not results:
raise TCAIntegrationError(f"未找到 job_id={job_id} 的扫描结果")
return results[0]
def get_project_overview(self) -> Dict:
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_overview", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("GET", url)
return result.get("data", {}) or {}
def get_project_overview_latest_scan(self) -> Dict:
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_overview_latest_scan", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("GET", url)
return result.get("data", {}) or {}
def get_issue_list(self) -> Dict:
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url("project_issue_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("GET", url)
return result
def _get_latest_scan_data(self, api_key: str) -> Optional[Dict]:
"""通用方法:获取指定扫描列表接口的最新一条数据(results[0]),无数据返回 None。
支持的 api_key: project_sca_scans, overview_cycscans, overview_clocscans, overview_dupscans, overview_lintscans
"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
url = self._build_url(api_key, org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
response = self._make_request("GET", url)
results = response.get("data", {}).get("results", [])
if not results:
return None
return results[0]
def get_sca_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("project_sca_scans")
def get_cyc_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_cycscans")
def get_cloc_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_clocscans")
def get_dup_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_dupscans")
def get_lint_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_lintscans")
# ---- 页面链接拼接 ----
def _build_page_url(self, suffix: str) -> str:
"""通用页面链接拼接:{base_url}/t/{org_sid}/p/{team_name}/repos/{repo_id}/projects/{project_id}/{suffix}"""
repo_id = self.get_pt_repo_id()
project_id = self.get_project_id()
base_url = self.config.base_url.rstrip('/')
return (f"{base_url}/t/{self.config.org_sid}/p/{self.config.team_name}"
f"/repos/{repo_id}/projects/{project_id}/{suffix}")
def get_job_dtail_url(self, job_id: int) -> str:
return self._build_page_url(f"jobs/{job_id}/progress")
def get_job_result_url(self, job_id: int) -> str:
return self._build_page_url(f"jobs/{job_id}/result")
def get_scan_overview_url(self) -> str:
return self._build_page_url("overview")
def get_scan_lint_url(self) -> str:
return self._build_page_url("lints?state=1")
def get_scan_sca_url(self, sca_scan_id: int) -> str:
return self._build_page_url(f"sca/{sca_scan_id}/overview")
def get_cycs_url(self) -> str:
return self._build_page_url("cycs/funcs")
def get_scan_dupfile_url(self) -> str:
return self._build_page_url("dupfiles?issue_state=1")
def get_scan_cloc_url(self) -> str:
return self._build_page_url("clocs")
class TCAPipeline:
"""TCA流水线集成类"""
def __init__(self, config: TCAConfig):
self.client = TCAClient(config)
self.config = config
def run_full_analysis(self) -> bool:
"""运行完整分析流程"""
# 1. 创建项目(或复用已有 project_team)
exist_project_teams = self.client.get_project_teams()
if not self.has_team_name(exist_project_teams, self.config.team_name):
project_team = self.client.create_project_team()
# 2. 登记代码库(或复用已有 repo)
try:
self.client.get_pt_repo_id(self.config.repo_url)
except TCAIntegrationError as e:
logger.info(f"未找到已有代码库: {self.config.repo_url}, 创建新代码库")
self.client.register_pt_repo()
# 3. 在该 repo 下创建项目(或复用已有 project)
try:
self.client.get_project_id()
except TCAIntegrationError as e:
logger.info(f"未找到已有项目: {self.config.repo_url}, 创建新项目")
self.client.create_project()
# 4. 启动扫描
start_scan_result = self.client.start_scan()
job_id = self.get_job_id(start_scan_result)
# 5. 等待完成
try:
scan_result = self.client.wait_for_scan_completion(job_id)
except TCAIntegrationError as e:
logger.error(f"扫描失败: {e}")
logger.error(f"扫描失败详情链接:{self.client.get_job_dtail_url(job_id)}")
return False
# 5. 如果代码无变更,触发增量扫描,会显示result_code为1,显示无需扫描
result_code, result_code_msg, result_msg = self.get_result_msg(scan_result)
if result_code == 1:
logger.info(
f"代码无变更,result_code: {result_code}, result_code_msg: {result_code_msg}, result_msg: {result_msg} 代码扫描结果为上一次扫描信息")
scan_info = self.client.get_project_overview()
quality_scan_source = self.client.get_project_overview_latest_scan()
elif result_code == 0:
logger.info(
f"全量扫描或代码有变更,result_code: {result_code}, result_code_msg: {result_code_msg}, result_msg: {result_msg} 代码扫描结果为最新扫描信息")
scan_info = self.client.get_scan_info(job_id)
quality_scan_source = scan_info
elif result_code >= 100:
logger.error(f"扫描失败: {result_code}, {result_code_msg}, {result_msg}")
logger.error(f"扫描失败详情链接:{self.client.get_job_dtail_url(job_id)}")
return False
# 5. 获取各维度扫描结果(overview 优先,为空时 fallback 到独立接口)
scan_collectors = [
{
"name": "代码扫描",
"overview_key": "lintscan",
"overview_empty_check": lambda info: not (info.get("lintscan") or {}).get("total"),
"overview_parser": self.get_lint_scan_result,
"fallback_fetcher": self.client.get_lint_scan_info,
"fallback_parser": self.get_lint_scan_detail_result,
"scan_id_extractor": lambda d: (d.get("scan") or {}).get("id"),
"revision_extractor": lambda d: (d.get("scan") or {}).get("current_revision", ""),
},
{
"name": "圈复杂度",
"overview_key": "cyclomaticcomplexityscan",
"overview_empty_check": lambda info: not ((info.get("cyclomaticcomplexityscan") or {}).get("custom_summary")),
"overview_parser": self.get_cyclomatic_complexity_result,
"fallback_fetcher": self.client.get_cyc_scan_info,
"fallback_parser": self.get_cyc_scan_result,
"scan_id_extractor": lambda d: d.get("scan") or d.get("id"),
"revision_extractor": lambda d: d.get("scan_revision", ""),
},
{
"name": "重复代码",
"overview_key": "duplicatescan",
"overview_empty_check": lambda info: self._is_all_none(info.get("duplicatescan") or {},
["duplicate_block_count", "total_duplicate_line_count", "duplicate_file_count"]),
"overview_parser": self.get_duplicate_code_result,
"fallback_fetcher": self.client.get_dup_scan_info,
"fallback_parser": self.get_dup_scan_result,
"scan_id_extractor": lambda d: d.get("scan") or d.get("id"),
"revision_extractor": lambda d: d.get("scan_revision", ""),
},
{
"name": "代码统计",
"overview_key": "clocscan",
"overview_empty_check": lambda info: self._is_all_none(info.get("clocscan") or {},
["code_line_num", "comment_line_num", "blank_line_num", "total_line_num"]),
"overview_parser": self.get_cloc_result,
"fallback_fetcher": self.client.get_cloc_scan_info,
"fallback_parser": self.get_cloc_scan_result,
"scan_id_extractor": lambda d: d.get("scan") or d.get("id"),
"revision_extractor": lambda d: d.get("scan_revision", ""),
},
]
for collector in scan_collectors:
self._collect_scan_result(collector, scan_info, job_id)
# 9. 获取 SCA 组成成分分析结果
sca_data = self.client.get_sca_scan_info()
sca_scan_id = None
if sca_data:
sca_scan_id = sca_data.get("id")
sca_scan_result = self.get_sca_scan_result(sca_data)
if sca_scan_id and int(sca_scan_id) != int(job_id):
# SCA 结果非本次扫描产生,显示对应的 commit_id
current_revision = (sca_data.get("scan") or {}).get("current_revision", "")
short_commit = current_revision[:8] if current_revision else "unknown"
logger.info(f"SCA 扫描结果(非本次扫描,当前任务 job_id: {sca_scan_id},来自 commit: {short_commit}): {sca_scan_result}")
else:
logger.info(f"SCA 扫描结果: {sca_scan_result}")
else:
logger.info("未获取到 SCA 扫描数据,跳过 SCA 结果输出")
# 10. 获取代码门禁结果
quality_gate_result = self.get_quality_gate_result(quality_scan_source)
logger.info(f"代码门禁结果: {quality_gate_result}")
# 11. 输出相关链接
logger.info(f"分析概览链接:{self.client.get_scan_overview_url()}")
logger.info(f"问题列表链接:{self.client.get_scan_lint_url()}")
if sca_scan_id:
logger.info(f"SCA 组成成分链接:{self.client.get_scan_sca_url(sca_scan_id)}")
logger.info(f"圈复杂度链接:{self.client.get_cycs_url()}")
logger.info(f"重复代码链接:{self.client.get_scan_dupfile_url()}")
logger.info(f"代码统计链接:{self.client.get_scan_cloc_url()}")
logger.info(f"任务结果链接:{self.client.get_job_result_url(job_id)}")
if quality_gate_result.get("status") == "success" or quality_gate_result.get("status") == "close":
return True
else:
return False
def get_job_id(self, result: dict) -> int:
try:
job_id = result["data"]["job"]["id"]
except (KeyError, TypeError):
raise TCAIntegrationError("响应格式不正确,未找到 data.job.id")
return job_id
def get_result_msg(self, result: dict) -> Tuple[int, str, str]:
try:
result_code = result["data"]["result_code"]
result_code_msg = result["data"]["result_code_msg"]
result_msg = result["data"]["result_msg"]
except (KeyError, TypeError):
raise TCAIntegrationError("响应格式不正确,未找到 data.result_code相关信息")
return result_code, result_code_msg, result_msg
@staticmethod
def _safe_get(data: dict, *keys):
"""安全地逐层获取嵌套字典值,任意一层为 None 则返回 None"""
for key in keys:
if isinstance(data, dict):
data = data.get(key)
else:
return None
return data
def get_lint_scan_result(self, results: dict) -> dict:
"""获取代码扫描结果(lintscan)"""
lint = results.get("lintscan") or {}
return {
"未处理问题数": self._safe_get(lint, "total", "state_detail", "active"),
"严重问题数": self._safe_get(lint, "total", "severity_detail", "fatal", "active") or 0,
"错误问题数": self._safe_get(lint, "total", "severity_detail", "error", "active") or 0,
"警告问题数": self._safe_get(lint, "total", "severity_detail", "warning", "active") or 0,
"提示问题数": self._safe_get(lint, "total", "severity_detail", "info", "active") or 0,
"问题总数(未聚合)": lint.get("issue_detail_num"),
"新增缺陷数": lint.get("issue_open_num"),
"修复缺陷数": lint.get("issue_fix_num"),
}
def get_lint_scan_detail_result(self, lint_data: dict) -> dict:
"""从 overview/lintscans 接口返回的单条数据中解析代码扫描结果"""
total = lint_data.get("total") or {}
return {
"未处理问题数": self._safe_get(total, "state_detail", "active") or 0,
"严重问题数": self._safe_get(total, "severity_detail", "fatal", "active") or 0,
"错误问题数": self._safe_get(total, "severity_detail", "error", "active") or 0,
"警告问题数": self._safe_get(total, "severity_detail", "warning", "active") or 0,
"提示问题数": self._safe_get(total, "severity_detail", "info", "active") or 0,
"问题总数(未聚合)": lint_data.get("issue_detail_num", 0),
"新增缺陷数": lint_data.get("issue_open_num", 0),
"修复缺陷数": lint_data.get("issue_fix_num", 0),
}
def get_cyclomatic_complexity_result(self, results: dict) -> dict:
"""获取圈复杂度结果(cyclomaticcomplexityscan)"""
cc = results.get("cyclomaticcomplexityscan") or {}
return {
"该分支所有超标方法个数": self._safe_get(cc, "custom_summary", "over_cc_func_count"),
"该分支所有超标方法平均复杂度": self._safe_get(cc, "custom_summary", "over_cc_func_average"),
"圈复杂度标准": cc.get("min_ccn"),
}
def get_cyc_scan_result(self, cyc_data: dict) -> dict:
"""从 overview/cycscans 接口返回的单条数据中解析圈复杂度结果"""
custom_summary = cyc_data.get("custom_summary") or {}
return {
"该分支所有超标方法个数": custom_summary.get("over_cc_func_count", 0),
"该分支所有超标方法平均复杂度": custom_summary.get("over_cc_func_average", 0),
"圈复杂度标准": custom_summary.get("min_ccn") or cyc_data.get("min_ccn", 0),
}
def get_duplicate_code_result(self, results: dict) -> dict:
"""获取重复代码结果(duplicatescan)"""
dup = results.get("duplicatescan") or {}
return {
"重复块数": dup.get("duplicate_block_count"),
"重复行数": dup.get("total_duplicate_line_count"),
"重复文件数": dup.get("duplicate_file_count"),
}
def get_dup_scan_result(self, dup_data: dict) -> dict:
"""从 overview/dupscans 接口返回的单条数据中解析重复代码结果"""
return {
"重复块数": dup_data.get("duplicate_block_count", 0),
"重复行数": dup_data.get("total_duplicate_line_count", 0),
"重复文件数": dup_data.get("duplicate_file_count", 0),
}
def get_cloc_result(self, results: dict) -> dict:
"""获取代码统计结果(clocscan)"""
cloc = results.get("clocscan") or {}
return {
"代码行数": cloc.get("code_line_num"),
"注释行数": cloc.get("comment_line_num"),
"空白行数": cloc.get("blank_line_num"),
"总行数": cloc.get("total_line_num"),
}
def get_cloc_scan_result(self, cloc_data: dict) -> dict:
"""从 overview/clocscans 接口返回的单条数据中解析代码统计结果"""
return {
"代码行数": cloc_data.get("code_line_num", 0),
"注释行数": cloc_data.get("comment_line_num", 0),
"空白行数": cloc_data.get("blank_line_num", 0),
"总行数": cloc_data.get("total_line_num", 0),
}
@staticmethod
def _risk_count(data_list: Optional[list], risk_key: str) -> int:
"""从 [{risk: ..., count: ...}, ...] 列表中提取指定 risk 的 count,未找到返回 0"""
if not data_list or not isinstance(data_list, list):
return 0
for item in data_list:
if isinstance(item, dict) and item.get("risk") == risk_key:
return item.get("count", 0)
return 0
def get_sca_scan_result(self, sca_data: dict) -> dict:
"""解析 SCA 扫描结果,输出文件信息、病毒、Copyright、License、安全审计、漏洞审计、License审计"""
file_num = sca_data.get("file_num", 0)
meta_data = sca_data.get("meta_data") or {}
source_reuse_rate = meta_data.get("source_reuse_rate", 0)
# 自研率 = 1 - 开源代码占比
source_reuse_rate_pct = round(source_reuse_rate * 100, 2)
self_rate_pct = round((1 - source_reuse_rate) * 100, 2)
malware_data = sca_data.get("malware_data")
copyright_data = sca_data.get("copyright_tampering_data")
license_tampering_data = sca_data.get("license_tampering_data")
base_audit_data = sca_data.get("base_audit_data")
cve_data = sca_data.get("cve_data")
license_data = sca_data.get("license_data")
return {
"文件总数": file_num,
"自研率": f"{self_rate_pct}%",
"开源代码占比": f"{source_reuse_rate_pct}%",
"病毒数": self._risk_count(malware_data, "Malware"),
"非病毒数": self._risk_count(malware_data, "Pass"),
"声明Copyright": self._risk_count(copyright_data, "Has"),
"未声明Copyright": self._risk_count(copyright_data, "Without"),
"Copyright篡改": self._risk_count(copyright_data, "Modified"),
"声明License": self._risk_count(license_tampering_data, "Has"),
"未声明License": self._risk_count(license_tampering_data, "Without"),
"License篡改": self._risk_count(license_tampering_data, "Modified"),
"安全审计-高危": self._risk_count(base_audit_data, "High"),
"安全审计-中危": self._risk_count(base_audit_data, "Medium"),
"安全审计-警告": self._risk_count(base_audit_data, "Warning"),
"安全审计-通过": self._risk_count(base_audit_data, "Pass"),
"安全审计-N/A": self._risk_count(base_audit_data, "N/A"),
"漏洞审计-严重": self._risk_count(cve_data, "Critical"),
"漏洞审计-高危": self._risk_count(cve_data, "High"),
"漏洞审计-中危": self._risk_count(cve_data, "Medium"),
"漏洞审计-低危": self._risk_count(cve_data, "Low"),
"漏洞审计-N/A": self._risk_count(cve_data, "NotAvailable"),
"License审计-高风险": self._risk_count(license_data, "High"),
"License审计-中风险": self._risk_count(license_data, "Middle"),
"License审计-低风险": self._risk_count(license_data, "Low"),
"License审计-N/A": self._risk_count(license_data, "NotAvailable"),
}
@staticmethod
def _is_all_none(data: dict, keys: list) -> bool:
"""判断字典中指定的所有 key 是否全为 None(或字典本身为空)"""
if not data:
return True
return all(data.get(k) is None for k in keys)
def _collect_scan_result(self, collector: dict, scan_info: dict, job_id: int):
"""通用的扫描结果收集逻辑:
1. 优先从 overview(scan_info)中取数据
2. overview 为空时 fallback 到独立接口
3. fallback 数据与 job_id 不一致时,标注"非本次扫描"
"""
name = collector["name"]
is_empty = collector["overview_empty_check"](scan_info)
if not is_empty:
result = collector["overview_parser"](scan_info)
logger.info(f"{name}结果: {result}")
return
fallback_data = collector["fallback_fetcher"]()
if not fallback_data:
logger.info(f"未获取到{name}扫描数据,跳过{name}结果输出")
return
scan_id = collector["scan_id_extractor"](fallback_data)
result = collector["fallback_parser"](fallback_data)
if scan_id and int(scan_id) != int(job_id):
revision = collector["revision_extractor"](fallback_data)
short_commit = revision[:8] if revision else "unknown"
logger.info(f"{name}结果(非本次扫描,当前任务 job_id: {scan_id},来自 commit: {short_commit}): {result}")
else:
logger.info(f"{name}结果: {result}")
def get_quality_gate_result(self, results: dict) -> dict:
"""获取质量门禁状态(qualityscan)"""
quality = results.get("qualityscan") or {}
return {
"status": quality.get("status"),
"description": quality.get("description"),
}
def has_team_name(self, response: dict, team_name: str) -> bool:
"""
判断接口返回的 project_team 数据中是否存在 name == team_name 的项目
:param response: 接口返回的完整字典数据
:return: True 表示存在名为 team_name 的团队,否则 False
"""
try:
teams = response.get("data", [])
for team in teams:
if team.get("name") == team_name:
return True
return False
except Exception as e:
TCAIntegrationError(f"解析 team 数据时出错: {e}")
return False
def _manual_load_dotenv(candidates: List[str]) -> int:
"""简易 .env 解析器:在未安装 python-dotenv 时,手动加载 KEY=VALUE 到 os.environ。
仅在变量未设置时覆盖。返回成功加载的变量数量。"""
loaded = 0
for path in candidates:
if not path:
continue
if os.path.exists(path) and os.path.isfile(path):
try:
with open(path, 'r', encoding='utf-8') as f:
for raw_line in f:
line = raw_line.strip()
if not line or line.startswith('#'):
continue
if '=' not in line:
continue
key, val = line.split('=', 1)
key = key.strip()
val = val.strip().strip('"').strip("'")
if key and key not in os.environ:
os.environ[key] = val
loaded += 1
logger.info(f"已从 .env 加载 {loaded} 个变量: {path}")
except Exception as e:
logger.warning(f"读取 .env 失败: {path} - {e}")
return loaded
def str_to_bool(value: str) -> bool:
"""将字符串转换为布尔值(忽略大小写)"""
return str(value).strip().lower() in ['true', '1', 't', 'y', 'yes']
def load_config_from_env() -> TCAConfig:
"""仅从环境变量与 .env 文件加载配置(不再读取 config.py)。
优先级:进程环境变量 > .env > 默认值
支持两处 .env:
- 与本脚本同目录的 .env
- 当前工作目录的 .env
"""
# 1) 优先尝试 python-dotenv
dotenv_loaded = False
try:
from dotenv import load_dotenv # type: ignore
from pathlib import Path
dotenv_paths = [
Path(__file__).with_name('.env'),
Path.cwd() / '.env'
]
for p in dotenv_paths:
if p.exists():
load_dotenv(dotenv_path=str(p), override=False)
dotenv_loaded = True
logger.info(f"已使用 python-dotenv 加载 .env: {p}")
break
except Exception:
pass
# 2) 若未通过 python-dotenv 加载,则手动加载
if not dotenv_loaded:
script_env = os.path.join(os.path.dirname(__file__), '.env')
cwd_env = os.path.join(os.getcwd(), '.env')
_manual_load_dotenv([script_env, cwd_env])
# 3) 读取环境变量
base_url = os.getenv('TCA_BASE_URL', 'https://tca.tencent.com')
tca_token = os.getenv('TCA_TOKEN', '')
user_id = os.getenv('TCA_USER_ID', '')
org_sid = os.getenv('TCA_ORG_SID', '')
team_name = os.getenv('TCA_TEAM_NAME', '')
repo_url = os.getenv('TCA_REPO_URL', '')
repo_branch = os.getenv('TCA_REPO_BRANCH', '')
repo_mr_branch = os.getenv('TCA_REPO_MR_BRANCH', '')
scm_account_id = os.getenv('TCA_SCM_ACCOUNT_ID', '')
scheme_id = int(os.getenv('TCA_SCHEME_ID', '0'))
incr_scan = os.getenv('TCA_INCR_SCAN', False)
force_create = os.getenv('TCA_FORCE_CREATE', False)
ignore_branch_issue = os.getenv('TCA_IGNORE_BRANCH_ISSUE', '')
max_wait_time = os.getenv('TCA_MAX_WAIT_TIME', '600')
return TCAConfig(
base_url=base_url,
tca_token=tca_token,
user_id=user_id,
org_sid=org_sid,
team_name=team_name,
repo_url=repo_url,
scm_account_id=int(scm_account_id),
repo_branch=repo_branch,
repo_mr_branch=repo_mr_branch,
scheme_id=scheme_id,
incr_scan=str_to_bool(incr_scan),
force_create=str_to_bool(force_create),
ignore_branch_issue=ignore_branch_issue,
max_wait_time=int(max_wait_time),
)
def main():
"""主函数 - 示例用法"""
# 加载配置(优先级:环境变量 > config.py > 默认值)
config = load_config_from_env()
logger.info(
f"已加载配置: base_url={config.base_url}, "
f"org_sid={'***' if config.org_sid else ''}, "
f"tca_token={'***' if config.tca_token else ''}, "
f"user_id={'***' if config.user_id else ''}, "
f"team_name={config.team_name}, "
f"repo_url={config.repo_url}, "
f"repo_branch={config.repo_branch}, "
f"repo_mr_branch={config.repo_mr_branch}, "
f"scm_account_id={config.scm_account_id}, "
f"scheme_id={config.scheme_id}, "
f"incr_scan={config.incr_scan}, "
f"force_create={config.force_create}, "
f"ignore_branch_issue={config.ignore_branch_issue}"
)
# 验证必要配置
if (not config.org_sid \
or not config.tca_token \
or not config.user_id \
or not config.team_name \
or not config.repo_url \
or not config.repo_branch \
or not config.scm_account_id \
or not config.scheme_id):
logger.error(
"缺少必要配置,请设置 TCA_USER_ID、TCA_TOKEN、TCA_ORG_SID、TCA_TEAM_NAME、TCA_REPO_URL、TCA_REPO_BRANCH、TCA_SCM_ACCOUNT_ID、TCA_SCHEME_ID")
sys.exit(1)
# 创建流水线实例
pipeline = TCAPipeline(config)
scan_result = pipeline.run_full_analysis()
if scan_result:
logger.info("流水线执行成功")
sys.exit(0)
else:
logger.error("流水线执行失败")
sys.exit(1)
if __name__ == "__main__":
main()
制品库分析脚本
环境变量
# TCA 平台服务地址
TCA_BASE_URL=https://tca.tencent.com
# API 访问令牌
TCA_USER_ID=your_user_id
TCA_TOKEN=your_token
# 团队唯一标识
TCA_ORG_SID=your_org_sid
# 项目唯一标识
TCA_TEAM_NAME=your_team_name
# 制品库名称
TCA_ARTIFACT_NAME=your_artifact_name
# 制品类型(binary/docker/RTOS 等)
TCA_ARTIFACT_TYPE=binary
# 分析方案 ID,可使用团队/项目分析方案,注意权限问题
TCA_SCHEME_ID=your_scheme_id
# 制品文件下载地址
TCA_ARTIFACT_URL=your_artifact_download_url
# 扫描最大等待时间(秒),默认600秒(10分钟)
TCA_MAX_WAIT_TIME=600
脚本内容
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
通过 API 启动制品库分析
"""
import os
import sys
import json
import requests
import logging
from typing import Dict, List, Optional, Any, Tuple
from dataclasses import dataclass
from time import time, sleep
from hashlib import sha256
# 日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout),
logging.FileHandler('tca_ci_artifact_saas.log')
]
)
logger = logging.getLogger(__name__)
# 开放API路径映射
TCA_OPEN_APIS = {
"project_team_list": "%s/server/main/api/orgs/{org_sid}/teams/",
"pt_repo_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/",
"project_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/",
"project_scan_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/{project_id}/scans/",
"job_detail": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/",
"project_sca_scans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/",
}
@dataclass
class TCAArtifactConfig:
"""TCA 制品库分析配置类"""
base_url: str
tca_token: str
user_id: str
org_sid: str
team_name: str
artifact_name: str
artifact_type: str
scheme_id: int
artifact_url: str
timeout: int = 30
max_retries: int = 3
max_wait_time: int = 600
class TCAIntegrationError(Exception):
"""TCA集成异常"""
pass
class TCAArtifactClient:
"""TCA 制品库 API 客户端"""
def __init__(self, config: TCAArtifactConfig):
self.config = config
self.session = requests.Session()
self._repo_id: Optional[int] = None
self._project_id: Optional[int] = None
def get_headers(self, user_id: Optional[str] = None, token: Optional[str] = None):
timestamp = int(time())
user_id = user_id or self.config.user_id
token = token or self.config.tca_token
token_sig = "%s%s#%s#%s%s" % (timestamp, user_id, token, user_id, timestamp)
ticket = sha256(token_sig.encode("utf-8")).hexdigest().upper()
return {
"TCA-USERID": user_id,
"TCA-TIMESTAMP": str(timestamp),
"TCA-TICKET": ticket
}
def _is_success_status(self, status_code: int) -> bool:
return 200 <= status_code < 300
def _make_request(self, method: str, url: str, data: Optional[Dict] = None,
params: Optional[Dict] = None) -> Dict:
"""发送API请求,url需为完整路径"""
for attempt in range(self.config.max_retries):
try:
headers = self.get_headers()
response = self.session.request(
method=method, url=url, headers=headers,
json=data, params=params, timeout=self.config.timeout
)
if self._is_success_status(response.status_code):
return response.json()
elif response.status_code == 401:
raise TCAIntegrationError("TCA Token无效或已过期")
elif response.status_code == 403:
raise TCAIntegrationError("权限不足,请检查团队ID和权限设置")
elif response.status_code == 404:
raise TCAIntegrationError("请求的资源不存在")
elif response.status_code >= 500:
logger.warning(f"服务器错误,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("服务器内部错误,请稍后重试")
sleep(2 ** attempt) # 指数退避
else:
raise TCAIntegrationError(f"API请求失败: {response.status_code} - {response.text}")
except requests.exceptions.Timeout:
logger.warning(f"请求超时,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("请求超时,请检查网络连接")
except requests.exceptions.ConnectionError:
logger.warning(f"连接错误,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("网络连接错误,请检查网络设置")
def _build_url(self, key: str, **kwargs: Any) -> str:
base = self.config.base_url.rstrip('/')
tpl = TCA_OPEN_APIS[key] % base
return tpl.format(**kwargs)
def get_or_create_team(self) -> Dict:
"""获取或创建项目"""
url = self._build_url("project_team_list", org_sid=self.config.org_sid)
result = self._make_request("GET", url)
teams = result.get("data", [])
for team in teams:
if team.get("name") == self.config.team_name:
logger.info(f"项目已存在: {self.config.team_name}")
return team
logger.info(f"创建项目: {self.config.team_name}")
return self._make_request("POST", url, data={
"name": self.config.team_name,
"display_name": self.config.team_name
})
def get_or_create_artifact_repo(self) -> int:
"""获取或创建制品库,返回 repo_id(首次获取后缓存)"""
if self._repo_id is not None:
return self._repo_id
url = self._build_url("pt_repo_list", org_sid=self.config.org_sid, team_name=self.config.team_name)
result = self._make_request("GET", url)
data = result.get("data") or {}
results = data.get("results") or []
for item in results:
if item.get("name") == self.config.artifact_name:
logger.info(f"制品库已存在: {self.config.artifact_name}")
self._repo_id = int(item["id"])
return self._repo_id
logger.info(f"创建制品库: {self.config.artifact_name}")
create_result = self._make_request("POST", url, data={
"name": self.config.artifact_name,
"artifact_type": self.config.artifact_type,
"created_from": "api"
})
self._repo_id = int(create_result.get("data", {}).get("id"))
return self._repo_id
def get_or_create_project(self) -> int:
"""获取或创建制品库分析项目,返回 project_id(首次获取后缓存)"""
if self._project_id is not None:
return self._project_id
repo_id = self.get_or_create_artifact_repo()
url = self._build_url("project_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id)
result = self._make_request("GET", url)
data = result.get("data") or {}
results = data.get("results") or []
for item in results:
item_scheme = (item.get("scan_scheme") or {}).get("id")
if item_scheme and int(item_scheme) == self.config.scheme_id:
logger.info(f"制品库分析项目已存在, id={item['id']}")
self._project_id = int(item["id"])
return self._project_id
logger.info(f"创建制品库分析项目, scheme_id={self.config.scheme_id}")
create_result = self._make_request("POST", url, data={
"name": f"{self.config.artifact_name}_project",
"global_scheme_id": self.config.scheme_id,
"created_from": "api"
})
self._project_id = int(create_result.get("data", {}).get("id"))
return self._project_id
def start_scan(self) -> Dict:
"""启动制品库分析任务"""
repo_id = self.get_or_create_artifact_repo()
project_id = self.get_or_create_project()
url = self._build_url("project_scan_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("POST", url, data={
"artifact_url": self.config.artifact_url,
"created_from": "api"
})
logger.info(f"启动制品库扫描任务结果: {result}")
return result
def wait_for_scan_completion(self, job_id: int) -> Dict:
"""等待分析任务完成"""
repo_id = self.get_or_create_artifact_repo()
project_id = self.get_or_create_project()
url = self._build_url("job_detail", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id,
project_id=project_id, job_id=job_id)
max_wait_time = self.config.max_wait_time
interval = 30
start_time = int(time())
while True:
results = self._make_request("GET", url)
data = results.get("data", {}) or {}
state = data.get("state")
result_code = data.get("result_code")
if state == 2:
if result_code == 0:
logger.info("扫描结果已出,结束等待")
return results
elif result_code and result_code >= 100:
raise TCAIntegrationError(
f"扫描失败: result_code={result_code}, result_msg={data.get('result_msg')}")
elapsed = int(time()) - start_time
if elapsed > max_wait_time:
raise TCAIntegrationError(f"扫描超过{max_wait_time}秒,扫描状态仍未改变,扫描失败")
logger.info(f"制品正在扫描中(当前 state: {state if state is not None else '无数据'}),等待{interval}秒后重试...")
sleep(interval)
def get_sca_scan_info(self) -> Optional[Dict]:
"""获取最新 SCA 分析结果(results 中第一条),无数据返回 None"""
repo_id = self.get_or_create_artifact_repo()
project_id = self.get_or_create_project()
url = self._build_url("project_sca_scans", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("GET", url)
results = result.get("data", {}).get("results", [])
if not results:
return None
return results[0]
# ---- 页面链接拼接 ----
def _build_page_url(self, suffix: str) -> str:
"""通用页面链接拼接"""
repo_id = self.get_or_create_artifact_repo()
project_id = self.get_or_create_project()
base_url = self.config.base_url.rstrip('/')
return (f"{base_url}/t/{self.config.org_sid}/p/{self.config.team_name}"
f"/artifacts/{repo_id}/projects/{project_id}/{suffix}")
def get_job_dtail_url(self, job_id: int) -> str:
return self._build_page_url(f"scans/{job_id}/scan-history/detail")
def get_scan_sca_overview_url(self, job_id: int) -> str:
return self._build_page_url(f"scans/{job_id}/overview")
class TCAArtifactPipeline:
"""TCA 制品库分析流水线"""
def __init__(self, config: TCAArtifactConfig):
self.client = TCAArtifactClient(config)
self.config = config
@staticmethod
def _risk_count(data_list: Optional[list], risk_key: str) -> int:
"""从 [{risk: ..., count: ...}, ...] 列表中提取指定 risk 的 count,未找到返回 0"""
if not data_list or not isinstance(data_list, list):
return 0
for item in data_list:
if isinstance(item, dict) and item.get("risk") == risk_key:
return item.get("count", 0)
return 0
def get_sca_scan_result(self, sca_data: dict) -> dict:
"""解析 SCA 扫描结果"""
file_num = sca_data.get("file_num", 0)
meta_data = sca_data.get("meta_data") or {}
source_reuse_rate = meta_data.get("source_reuse_rate") or 0
source_reuse_rate_pct = round(source_reuse_rate * 100, 2)
self_rate_pct = round((1 - source_reuse_rate) * 100, 2)
malware_data = sca_data.get("malware_data")
copyright_data = sca_data.get("copyright_tampering_data")
license_tampering_data = sca_data.get("license_tampering_data")
base_audit_data = sca_data.get("base_audit_data")
cve_data = sca_data.get("cve_data")
license_data = sca_data.get("license_data")
return {
"文件总数": file_num,
"病毒数": self._risk_count(malware_data, "Malware"),
"非病毒数": self._risk_count(malware_data, "Pass"),
"安全审计-高危": self._risk_count(base_audit_data, "High"),
"安全审计-中危": self._risk_count(base_audit_data, "Medium"),
"安全审计-警告": self._risk_count(base_audit_data, "Warning"),
"安全审计-通过": self._risk_count(base_audit_data, "Pass"),
"安全审计-N/A": self._risk_count(base_audit_data, "N/A"),
"漏洞审计-严重": self._risk_count(cve_data, "Critical"),
"漏洞审计-高危": self._risk_count(cve_data, "High"),
"漏洞审计-中危": self._risk_count(cve_data, "Medium"),
"漏洞审计-低危": self._risk_count(cve_data, "Low"),
"漏洞审计-N/A": self._risk_count(cve_data, "NotAvailable"),
"License审计-高风险": self._risk_count(license_data, "High"),
"License审计-中风险": self._risk_count(license_data, "Middle"),
"License审计-低风险": self._risk_count(license_data, "Low"),
"License审计-N/A": self._risk_count(license_data, "NotAvailable"),
}
def run_full_analysis(self) -> bool:
"""运行完整制品库分析流程"""
# 1. 创建/获取项目
self.client.get_or_create_team()
# 2. 创建/获取制品库(结果缓存到 _repo_id)
self.client.get_or_create_artifact_repo()
# 3. 创建/获取分析项目(结果缓存到 _project_id)
self.client.get_or_create_project()
# 4. 启动扫描
start_result = self.client.start_scan()
try:
job_id = start_result["data"]["job_id"]
except (KeyError, TypeError):
raise TCAIntegrationError("响应格式不正确,未找到 data.job_id")
# 5. 等待完成
try:
self.client.wait_for_scan_completion(job_id)
except TCAIntegrationError as e:
logger.error(f"扫描失败: {e}")
logger.error(f"扫描失败详情链接:{self.client.get_job_dtail_url(job_id)}")
return False
# 6. 获取 SCA 组成成分分析结果
sca_data = self.client.get_sca_scan_info()
if sca_data:
sca_scan_id = (sca_data.get("scan") or {}).get("id")
sca_scan_result = self.get_sca_scan_result(sca_data)
if sca_scan_id and int(sca_scan_id) != int(job_id):
logger.info(f"SCA 扫描结果(非本次扫描,当前任务 job_id: {sca_scan_id} ): {sca_scan_result}")
else:
logger.info(f"SCA 扫描结果: {sca_scan_result}")
else:
logger.info("未获取到 SCA 扫描数据,跳过 SCA 结果输出")
# 7. 输出相关链接
logger.info(f"SCA 扫描分析概览链接:{self.client.get_scan_sca_overview_url(job_id)}")
return True
def _manual_load_dotenv(candidates: List[str]) -> int:
"""简易 .env 解析器:在未安装 python-dotenv 时,手动加载 KEY=VALUE 到 os.environ。
仅在变量未设置时覆盖。返回成功加载的变量数量。"""
loaded = 0
for path in candidates:
if not path:
continue
if os.path.exists(path) and os.path.isfile(path):
try:
with open(path, 'r', encoding='utf-8') as f:
for raw_line in f:
line = raw_line.strip()
if not line or line.startswith('#'):
continue
if '=' not in line:
continue
key, val = line.split('=', 1)
key = key.strip()
val = val.strip().strip('"').strip("'")
if key and key not in os.environ:
os.environ[key] = val
loaded += 1
logger.info(f"已从 .env 加载 {loaded} 个变量: {path}")
except Exception as e:
logger.warning(f"读取 .env 失败: {path} - {e}")
return loaded
def load_config_from_env() -> TCAArtifactConfig:
"""仅从环境变量与 .env 文件加载配置。
优先级:进程环境变量 > .env > 默认值
支持两处 .env:
- 与本脚本同目录的 .env
- 当前工作目录的 .env
"""
# 1) 优先尝试 python-dotenv
dotenv_loaded = False
try:
from dotenv import load_dotenv # type: ignore
from pathlib import Path
for p in [Path(__file__).with_name('.env'), Path.cwd() / '.env']:
if p.exists():
load_dotenv(dotenv_path=str(p), override=False)
dotenv_loaded = True
logger.info(f"已使用 python-dotenv 加载 .env: {p}")
break
except Exception:
pass
# 2) 若未通过 python-dotenv 加载,则手动加载
if not dotenv_loaded:
_manual_load_dotenv([
os.path.join(os.path.dirname(__file__), '.env'),
os.path.join(os.getcwd(), '.env')
])
return TCAArtifactConfig(
base_url=os.getenv('TCA_BASE_URL', 'https://tca.tencent.com'),
tca_token=os.getenv('TCA_TOKEN', ''),
user_id=os.getenv('TCA_USER_ID', ''),
org_sid=os.getenv('TCA_ORG_SID', ''),
team_name=os.getenv('TCA_TEAM_NAME', ''),
artifact_name=os.getenv('TCA_ARTIFACT_NAME', ''),
artifact_type=os.getenv('TCA_ARTIFACT_TYPE', 'binary'),
scheme_id=int(os.getenv('TCA_SCHEME_ID', '0')),
artifact_url=os.getenv('TCA_ARTIFACT_URL', ''),
max_wait_time=int(os.getenv('TCA_MAX_WAIT_TIME', '600')),
)
def main():
"""主函数 - 制品库分析"""
config = load_config_from_env()
logger.info(
f"已加载配置: base_url={config.base_url}, "
f"org_sid={'***' if config.org_sid else ''}, "
f"tca_token={'***' if config.tca_token else ''}, "
f"user_id={'***' if config.user_id else ''}, "
f"team_name={config.team_name}, "
f"artifact_name={config.artifact_name}, "
f"artifact_type={config.artifact_type}, "
f"scheme_id={config.scheme_id}, "
f"artifact_url={config.artifact_url}"
)
if not all([config.org_sid, config.tca_token, config.user_id,
config.team_name, config.artifact_name, config.scheme_id,
config.artifact_url]):
logger.error(
"缺少必要配置,请设置 TCA_USER_ID、TCA_TOKEN、TCA_ORG_SID、"
"TCA_TEAM_NAME、TCA_ARTIFACT_NAME、TCA_SCHEME_ID、TCA_ARTIFACT_URL")
sys.exit(1)
pipeline = TCAArtifactPipeline(config)
if pipeline.run_full_analysis():
logger.info("制品库分析流水线执行成功")
sys.exit(0)
else:
logger.error("制品库分析流水线执行失败")
sys.exit(1)
if __name__ == "__main__":
main()
源码包分析脚本
环境变量
执行脚本时,可以注入环境变量,动态调整参数,实现自动化集成。
# TCA 平台服务地址
TCA_BASE_URL=https://tca.tencent.com
# API 访问令牌
TCA_USER_ID=your_user_id
TCA_TOKEN=your_token
# 团队唯一标识
TCA_ORG_SID=your_org_sid
# 项目唯一标识
TCA_TEAM_NAME=your_team_name
# 源码包名称
TCA_SOURCE_PKG_NAME=your_source_pkg_name
# 源码包版本
TCA_SOURCE_PKG_VERSION=your_source_pkg_version
# 分析方案 ID,可使用团队/项目分析方案,注意权限问题
TCA_SCHEME_ID=your_scheme_id
# 源码包文件下载地址(.zip/.tar.gz/.tar)
TCA_ARTIFACT_URL=https://example.com/path/to/source.zip
# 扫描最大等待时间(秒),默认600秒(10分钟)
TCA_MAX_WAIT_TIME=600
脚本内容
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
通过 API 启动源码包分析
"""
import os
import sys
import json
import requests
import logging
from typing import Dict, List, Optional, Any
from dataclasses import dataclass
from time import time, sleep
from hashlib import sha256
# 日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout),
logging.FileHandler('tca_ci_sourcepkg_saas.log')
]
)
logger = logging.getLogger(__name__)
# 开放API路径映射
TCA_OPEN_APIS = {
"project_team_list": "%s/server/main/api/orgs/{org_sid}/teams/",
"pt_repo_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/",
"project_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/",
"project_scan_list": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/artifact/repos/{repo_id}/projects/{project_id}/scans/",
"job_detail": "%s/server/main/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/jobs/{job_id}/detail/",
"project_analysis_scan_list": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/scaninfos/",
"project_issue_list": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/codelint/issues/",
"project_sca_scans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/sca/scans/",
"overview_lintscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/lintscans/",
"overview_cycscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/cycscans/",
"overview_dupscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/dupscans/",
"overview_clocscans": "%s/server/analysis/api/orgs/{org_sid}/teams/{team_name}/repos/{repo_id}/projects/{project_id}/overview/clocscans/",
}
@dataclass
class TCASourcePkgConfig:
"""TCA源码包分析配置类"""
base_url: str
tca_token: str
user_id: str
org_sid: str
team_name: str
source_pkg_name: str
source_pkg_version: str
scheme_id: int
artifact_url: str
timeout: int = 30
max_retries: int = 3
max_wait_time: int = 600
class TCAIntegrationError(Exception):
"""TCA集成异常"""
pass
class TCASourcePkgClient:
"""TCA 源码包分析 API 客户端
"""
def __init__(self, config: TCASourcePkgConfig):
self.config = config
self.session = requests.Session()
self._repo_id: Optional[int] = None
self._project_id: Optional[int] = None
def get_headers(self, user_id: Optional[str] = None, token: Optional[str] = None):
timestamp = int(time())
user_id = user_id or self.config.user_id
token = token or self.config.tca_token
token_sig = "%s%s#%s#%s%s" % (timestamp, user_id, token, user_id, timestamp)
ticket = sha256(token_sig.encode("utf-8")).hexdigest().upper()
return {
"TCA-USERID": user_id,
"TCA-TIMESTAMP": str(timestamp),
"TCA-TICKET": ticket
}
def _is_success_status(self, status_code: int) -> bool:
return 200 <= status_code < 300
def _make_request(self, method: str, url: str, data: Optional[Dict] = None,
params: Optional[Dict] = None) -> Dict:
"""发送API请求"""
for attempt in range(self.config.max_retries):
try:
headers = self.get_headers()
response = self.session.request(
method=method, url=url, headers=headers,
json=data, params=params, timeout=self.config.timeout
)
if self._is_success_status(response.status_code):
return response.json()
elif response.status_code == 401:
raise TCAIntegrationError("TCA Token无效或已过期")
elif response.status_code == 403:
raise TCAIntegrationError("权限不足,请检查团队ID和权限设置")
elif response.status_code == 404:
raise TCAIntegrationError("请求的资源不存在")
elif response.status_code >= 500:
logger.warning(f"服务器错误,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("服务器内部错误,请稍后重试")
sleep(2 ** attempt)
else:
raise TCAIntegrationError(f"API请求失败: {response.status_code} - {response.text}")
except requests.exceptions.Timeout:
logger.warning(f"请求超时,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("请求超时,请检查网络连接")
except requests.exceptions.ConnectionError:
logger.warning(f"连接错误,第{attempt + 1}次重试...")
if attempt == self.config.max_retries - 1:
raise TCAIntegrationError("网络连接错误,请检查网络设置")
def _build_url(self, key: str, **kwargs: Any) -> str:
base = self.config.base_url.rstrip('/')
tpl = TCA_OPEN_APIS[key] % base
return tpl.format(**kwargs)
# ==================== 前置步骤====================
def get_or_create_team(self) -> Dict:
"""获取或创建项目"""
url = self._build_url("project_team_list", org_sid=self.config.org_sid)
result = self._make_request("GET", url)
# 接口返回 data 为列表
teams = result.get("data", [])
for team in teams:
if team.get("name") == self.config.team_name:
logger.info(f"项目已存在: {self.config.team_name}")
return team
logger.info(f"创建项目: {self.config.team_name}")
return self._make_request("POST", url, data={
"name": self.config.team_name,
"display_name": self.config.team_name
})
def get_or_create_source_pkg(self) -> int:
"""获取或创建源码包,返回 repo_id """
if self._repo_id is not None:
return self._repo_id
url = self._build_url("pt_repo_list", org_sid=self.config.org_sid, team_name=self.config.team_name)
result = self._make_request("GET", url)
data = result.get("data") or {}
results = data.get("results") or []
for item in results:
if item.get("name") == self.config.source_pkg_name:
logger.info(f"源码包已存在: {self.config.source_pkg_name}")
self._repo_id = int(item["id"])
return self._repo_id
logger.info(f"创建源码包: {self.config.source_pkg_name}")
create_result = self._make_request("POST", url, data={
"scm_url": self.config.source_pkg_name,
"scm_type": "package",
"created_from": "api"
})
self._repo_id = int(create_result.get("data", {}).get("id"))
return self._repo_id
def get_or_create_project(self) -> int:
"""获取或创建源码包分析项目,返回 project_id """
if self._project_id is not None:
return self._project_id
repo_id = self.get_or_create_source_pkg()
url = self._build_url("project_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id)
result = self._make_request("GET", url)
data = result.get("data") or {}
results = data.get("results") or []
for item in results:
item_scheme = (item.get("scan_scheme") or {}).get("id")
branch = item.get("branch") or ""
if item_scheme and int(item_scheme) == self.config.scheme_id and branch == self.config.source_pkg_version:
logger.info(f"源码包分析项目已存在, id={item['id']}")
self._project_id = int(item["id"])
return self._project_id
logger.info(f"创建源码包分析项目, scheme_id={self.config.scheme_id}")
create_result = self._make_request("POST", url, data={
"branch": self.config.source_pkg_version,
"global_scheme_id": self.config.scheme_id,
"created_from": "api"
})
self._project_id = int(create_result.get("data", {}).get("id"))
return self._project_id
def start_scan(self) -> Dict:
"""启动源码包分析任务"""
repo_id = self.get_or_create_source_pkg()
project_id = self.get_or_create_project()
url = self._build_url("project_scan_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("POST", url, data={
"artifact_url": self.config.artifact_url,
"created_from": "api"
})
logger.info(f"启动源码包扫描任务结果: {result}")
return result
def wait_for_scan_completion(self, job_id: int) -> Dict:
"""等待分析任务完成"""
repo_id = self.get_or_create_source_pkg()
project_id = self.get_or_create_project()
url = self._build_url("job_detail", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id,
project_id=project_id, job_id=job_id)
max_wait_time = self.config.max_wait_time
interval = 30
start_time = int(time())
while True:
results = self._make_request("GET", url)
data = results.get("data", {}) or {}
state = data.get("state")
result_code = data.get("result_code")
if state == 2:
if result_code == 0:
logger.info("扫描结果已出,结束等待")
return results
if result_code and result_code >= 100:
raise TCAIntegrationError(
f"扫描失败: result_code={result_code}, result_msg={data.get('result_msg')}")
elapsed = int(time()) - start_time
if elapsed > max_wait_time:
raise TCAIntegrationError(f"扫描超过{max_wait_time}秒,扫描状态仍未改变,扫描失败")
logger.info(f"源码包正在扫描中(当前 state: {state if state is not None else '无数据'}),等待{interval}秒后重试...")
sleep(interval)
# ==================== 获取分析结果 ====================
def get_scan_info(self, job_id: Optional[int] = None) -> Dict:
"""获取分析概览"""
repo_id = self.get_or_create_source_pkg()
project_id = self.get_or_create_project()
url = self._build_url("project_analysis_scan_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
params = {"id": job_id} if job_id else None
response = self._make_request("GET", url, params=params)
results = response.get("data", {}).get("results", [])
if not results:
raise TCAIntegrationError("未找到扫描结果")
return results[0]
def get_issue_list(self) -> Dict:
"""获取代码检查问题列表"""
repo_id = self.get_or_create_source_pkg()
project_id = self.get_or_create_project()
url = self._build_url("project_issue_list", org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
return self._make_request("GET", url)
def _get_latest_scan_data(self, api_key: str) -> Optional[Dict]:
"""通用方法:获取指定扫描列表接口的最新一条数据(results[0]),无数据返回 None"""
repo_id = self.get_or_create_source_pkg()
project_id = self.get_or_create_project()
url = self._build_url(api_key, org_sid=self.config.org_sid,
team_name=self.config.team_name, repo_id=repo_id, project_id=project_id)
result = self._make_request("GET", url)
results = result.get("data", {}).get("results", [])
return results[0] if results else None
def get_lint_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_lintscans")
def get_cyc_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_cycscans")
def get_dup_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_dupscans")
def get_cloc_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("overview_clocscans")
def get_sca_scan_info(self) -> Optional[Dict]:
return self._get_latest_scan_data("project_sca_scans")
# ---- 页面链接拼接 ----
def _build_page_url(self, suffix: str) -> str:
repo_id = self.get_or_create_source_pkg()
project_id = self.get_or_create_project()
base_url = self.config.base_url.rstrip('/')
return (f"{base_url}/t/{self.config.org_sid}/p/{self.config.team_name}"
f"/repos/{repo_id}/projects/{project_id}/{suffix}")
def get_job_detail_url(self, job_id: int) -> str:
return self._build_page_url(f"scans/{job_id}/scan-history/progress")
def get_overview_url(self, job_id: int) -> str:
return self._build_page_url(f"scans/{job_id}/overview")
class TCASourcePkgPipeline:
"""TCA 源码包分析流水线"""
def __init__(self, config: TCASourcePkgConfig):
self.client = TCASourcePkgClient(config)
self.config = config
@staticmethod
def _safe_get(data: dict, *keys) -> Any:
"""安全地从嵌套字典中取值"""
for key in keys:
if not isinstance(data, dict):
return None
data = data.get(key)
return data
def get_lint_result(self, scan_info: dict) -> dict:
"""获取代码检查结果"""
lint = scan_info.get("lintscan") or {}
total = lint.get("total") or {}
return {
"未处理问题数": (total.get("state_detail") or {}).get("active", 0),
"严重问题数": (total.get("severity_detail", {}).get("fatal") or {}).get("active", 0),
"错误问题数": (total.get("severity_detail", {}).get("error") or {}).get("active", 0),
"警告问题数": (total.get("severity_detail", {}).get("warning") or {}).get("active", 0),
"提示问题数": (total.get("severity_detail", {}).get("info") or {}).get("active", 0),
"问题总数(未聚合)": lint.get("issue_detail_num", 0),
"新增缺陷数": lint.get("issue_open_num", 0),
"修复缺陷数": lint.get("issue_fix_num", 0),
}
def get_cc_result(self, scan_info: dict) -> dict:
"""获取圈复杂度结果"""
cc = scan_info.get("cyclomaticcomplexityscan") or {}
custom_summary = cc.get("custom_summary") or {}
return {
"超标方法个数": custom_summary.get("over_cc_func_count", 0),
"超标方法平均复杂度": custom_summary.get("over_cc_func_average", 0),
"圈复杂度标准": cc.get("min_ccn", 0),
}
def get_dup_result(self, scan_info: dict) -> dict:
"""获取重复代码结果"""
dup = scan_info.get("duplicatescan") or {}
return {
"重复块数": dup.get("duplicate_block_count", 0),
"重复行数": dup.get("total_duplicate_line_count", 0),
"重复文件数": dup.get("duplicate_file_count", 0),
}
def get_cloc_result(self, scan_info: dict) -> dict:
"""获取代码统计结果"""
cloc = scan_info.get("clocscan") or {}
return {
"代码行数": cloc.get("code_line_num", 0),
"注释行数": cloc.get("comment_line_num", 0),
"空白行数": cloc.get("blank_line_num", 0),
"总行数": cloc.get("total_line_num", 0),
}
def get_quality_gate_result(self, scan_info: dict) -> dict:
"""获取质量门禁结果"""
quality = scan_info.get("qualityscan") or {}
return {
"status": quality.get("status"),
"description": quality.get("description"),
}
def run_full_analysis(self) -> bool:
"""运行完整源码包分析流程"""
# 1. 创建/获取项目
self.client.get_or_create_team()
# 2. 创建/获取源码包
self.client.get_or_create_source_pkg()
# 3. 创建/获取分析项目
self.client.get_or_create_project()
# 4. 启动扫描
start_result = self.client.start_scan()
try:
job_id = start_result["data"]["job_id"]
except (KeyError, TypeError):
raise TCAIntegrationError("响应格式不正确,未找到 data.job_id")
logger.info(f"扫描任务已启动, job_id={job_id}")
logger.info(f"任务详情链接:{self.client.get_job_detail_url(job_id)}")
# 5. 等待完成
try:
scan_result = self.client.wait_for_scan_completion(job_id)
except TCAIntegrationError as e:
logger.error(f"扫描失败: {e}")
logger.error(f"任务详情链接:{self.client.get_job_detail_url(job_id)}")
return False
logger.info("扫描任务完成, result_code=0")
# 6. 获取分析结果
scan_info = self.client.get_scan_info(job_id)
logger.info("=== 代码检查结果 ===")
logger.info(json.dumps(self.get_lint_result(scan_info), indent=2, ensure_ascii=False))
logger.info("=== 圈复杂度结果 ===")
logger.info(json.dumps(self.get_cc_result(scan_info), indent=2, ensure_ascii=False))
logger.info("=== 重复代码结果 ===")
logger.info(json.dumps(self.get_dup_result(scan_info), indent=2, ensure_ascii=False))
logger.info("=== 代码统计结果 ===")
logger.info(json.dumps(self.get_cloc_result(scan_info), indent=2, ensure_ascii=False))
logger.info("=== 质量门禁结果 ===")
quality_result = self.get_quality_gate_result(scan_info)
logger.info(json.dumps(quality_result, indent=2, ensure_ascii=False))
if quality_result.get("status") == "failure":
logger.warning(f"质量门禁未通过: {quality_result.get('description')}")
logger.info(f"分析概览链接:{self.client.get_overview_url(job_id)}")
logger.info("源码包分析流程执行完成")
return True
def _manual_load_dotenv(candidates: List[str]) -> int:
"""简易 .env 解析器:在未安装 python-dotenv 时,手动加载 KEY=VALUE 到 os.environ。
仅在变量未设置时覆盖。返回成功加载的变量数量。"""
loaded = 0
for path in candidates:
if not path:
continue
if os.path.exists(path) and os.path.isfile(path):
try:
with open(path, 'r', encoding='utf-8') as f:
for raw_line in f:
line = raw_line.strip()
if not line or line.startswith('#'):
continue
if '=' not in line:
continue
key, val = line.split('=', 1)
key = key.strip()
val = val.strip().strip('"').strip("'")
if key and key not in os.environ:
os.environ[key] = val
loaded += 1
logger.info(f"已从 .env 加载 {loaded} 个变量: {path}")
except Exception as e:
logger.warning(f"读取 .env 失败: {path} - {e}")
return loaded
def load_config_from_env() -> TCASourcePkgConfig:
"""仅从环境变量与 .env 文件加载配置。
优先级:进程环境变量 > .env > 默认值
支持两处 .env:
- 与本脚本同目录的 .env
- 当前工作目录的 .env
"""
# 1) 优先尝试 python-dotenv
dotenv_loaded = False
try:
from dotenv import load_dotenv # type: ignore
from pathlib import Path
for p in [Path(__file__).with_name('.env'), Path.cwd() / '.env']:
if p.exists():
load_dotenv(dotenv_path=str(p), override=False)
dotenv_loaded = True
logger.info(f"已使用 python-dotenv 加载 .env: {p}")
break
except Exception:
pass
# 2) 若未通过 python-dotenv 加载,则手动加载
if not dotenv_loaded:
_manual_load_dotenv([
os.path.join(os.path.dirname(__file__), '.env'),
os.path.join(os.getcwd(), '.env')
])
return TCASourcePkgConfig(
base_url=os.getenv('TCA_BASE_URL', 'https://tca.tencent.com').rstrip("/"),
tca_token=os.getenv('TCA_TOKEN', ''),
user_id=os.getenv('TCA_USER_ID', ''),
org_sid=os.getenv('TCA_ORG_SID', ''),
team_name=os.getenv('TCA_TEAM_NAME', ''),
source_pkg_name=os.getenv('TCA_SOURCE_PKG_NAME', ''),
source_pkg_version=os.getenv('TCA_SOURCE_PKG_VERSION', ''),
scheme_id=int(os.getenv('TCA_SCHEME_ID', '0')),
artifact_url=os.getenv('TCA_ARTIFACT_URL', ''),
max_wait_time=int(os.getenv('TCA_MAX_WAIT_TIME', '600')),
)
def main():
"""主函数 - 源码包分析"""
config = load_config_from_env()
# 参数校验
if not all([config.tca_token, config.user_id, config.org_sid, config.team_name,
config.source_pkg_name, config.source_pkg_version, config.scheme_id, config.artifact_url]):
logger.error("缺少必要的环境变量,请检查配置")
sys.exit(1)
pipeline = TCASourcePkgPipeline(config)
try:
success = pipeline.run_full_analysis()
if not success:
sys.exit(1)
except TCAIntegrationError as e:
logger.error(f"源码包分析失败: {e}")
sys.exit(1)
except Exception as e:
logger.error(f"未知错误: {e}")
sys.exit(1)
if __name__ == "__main__":
main()
Postman/Apifox 接口集合
同时为了便于开发者使用,我们提供了可导入 API 管理工具(如 Postman、Apifox 等)的 JSON 文件,用户可直接导入后快速调试接口。
{
"info": {
"name": "TCA API触发分析(SAAS 环境)",
"_postman_id": "tca-api-triggered-analysis-saas-collection",
"description": "TCA (Tencent Code Analysis) API触发分析接口集合(SAAS 版本),包含代码分析、制品库分析与源码包分析全部接口。\n\n鉴权方式:Pre-request Script 自动计算 TCA-USERID / TCA-TIMESTAMP / TCA-TICKET 签名 Header。\n\n由 tca_ci_git_saas.py + tca_ci_artifact_saas.py + tca_ci_sourcepkg_saas.py 导出。",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"variable": [
{ "key": "base_url", "value": "https://tca.tencent.com", "type": "string" },
{ "key": "user_id", "value": "", "type": "string" },
{ "key": "tca_token", "value": "", "type": "string" },
{ "key": "org_sid", "value": "", "type": "string" },
{ "key": "team_name", "value": "", "type": "string" },
{ "key": "repo_id", "value": "", "type": "string" },
{ "key": "project_id", "value": "", "type": "string" },
{ "key": "job_id", "value": "", "type": "string" },
{ "key": "scheme_id", "value": "", "type": "string" },
{ "key": "scm_account_id", "value": "", "type": "string" },
{ "key": "repo_url", "value": "", "type": "string" },
{ "key": "repo_branch", "value": "", "type": "string" },
{ "key": "incr_scan", "value": "false", "type": "string" },
{ "key": "force_create", "value": "false", "type": "string" },
{ "key": "ignore_branch_issue", "value": "", "type": "string" },
{ "key": "artifact_repo_id", "value": "", "type": "string" },
{ "key": "artifact_project_id", "value": "", "type": "string" },
{ "key": "artifact_name", "value": "", "type": "string" },
{ "key": "artifact_type", "value": "binary", "type": "string" },
{ "key": "artifact_url", "value": "", "type": "string" },
{ "key": "scan_id", "value": "", "type": "string" },
{ "key": "source_pkg_repo_id", "value": "", "type": "string" },
{ "key": "source_pkg_project_id", "value": "", "type": "string" },
{ "key": "source_pkg_name", "value": "", "type": "string" },
{ "key": "source_pkg_version", "value": "", "type": "string" },
{ "key": "source_pkg_url", "value": "", "type": "string" }
],
"event": [
{
"listen": "prerequest",
"script": {
"type": "text/javascript",
"exec": [
"// ========== TCA SAAS 签名自动计算(Pre-request Script) ==========",
"const userId = pm.collectionVariables.get('user_id') || pm.environment.get('user_id') || '';",
"const tcaToken = pm.collectionVariables.get('tca_token') || pm.environment.get('tca_token') || '';",
"",
"if (!userId || !tcaToken) {",
" console.warn('TCA 签名所需的 user_id 或 tca_token 未设置,请在环境或集合变量中配置。');",
"} else {",
" const timestamp = Math.floor(Date.now() / 1000).toString();",
" const raw = timestamp + userId + '#' + tcaToken + '#' + userId + timestamp;",
" const ticket = CryptoJS.SHA256(raw).toString(CryptoJS.enc.Hex).toUpperCase();",
"",
" pm.request.headers.upsert({ key: 'TCA-USERID', value: userId });",
" pm.request.headers.upsert({ key: 'TCA-TIMESTAMP', value: timestamp });",
" pm.request.headers.upsert({ key: 'TCA-TICKET', value: ticket });",
"}"
]
}
}
],
"item": [
{
"name": "项目",
"item": [
{
"name": "获取项目列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", ""]
},
"description": "获取当前团队下的项目列表。\n\n对应 API key: project_team_list\n对应方法: TCAClient.get_project_teams() / TCAArtifactClient.get_or_create_team()"
},
"response": []
},
{
"name": "创建项目",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"name\": \"{{team_name}}\",\n \"display_name\": \"{{team_name}}\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", ""]
},
"description": "创建新的项目。\n\n对应 API key: project_team_list\n对应方法: TCAClient.create_project_team() / TCAArtifactClient.get_or_create_team()"
},
"response": []
}
]
},
{
"name": "代码库分析",
"item": [
{
"name": "代码库",
"item": [
{
"name": "获取项目代码库列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", ""]
},
"description": "获取项目下的代码库列表。\n\n对应 API key: pt_repo_list\n对应方法: TCAClient.get_pt_repos()"
},
"response": []
},
{
"name": "登记代码库",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"scm_url\": \"{{repo_url}}\",\n \"scm_type\": \"git\",\n \"scm_auth\": {\n \"auth_type\": \"password\",\n \"scm_account\": {{scm_account_id}}\n },\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", ""]
},
"description": "在项目下登记新的代码库。\n\n对应 API key: pt_repo_list\n对应方法: TCAClient.register_pt_repo()"
},
"response": []
}
]
},
{
"name": "分析项目",
"item": [
{
"name": "获取分析项目列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", ""]
},
"description": "获取代码库下的分析项目列表。\n\n对应 API key: project_list\n对应方法: TCAClient.get_projects()"
},
"response": []
},
{
"name": "创建分析项目",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"branch\": \"{{repo_branch}}\",\n \"global_scheme_id\": {{scheme_id}},\n \"use_scheme_template\": true,\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", ""]
},
"description": "创建新的分析项目。\n\n对应 API key: project_list\n对应方法: TCAClient.create_project()"
},
"response": []
}
]
},
{
"name": "扫描任务",
"item": [
{
"name": "启动扫描任务",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"incr_scan\": {{incr_scan}},\n \"force_create\": {{force_create}},\n \"ignore_branch_issue\": \"{{ignore_branch_issue}}\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/scans/create/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "scans", "create", ""]
},
"description": "启动代码扫描任务。\n\n对应 API key: project_scan_list\n对应方法: TCAClient.start_scan()"
},
"response": []
},
{
"name": "查询扫描任务详情",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/jobs/{{job_id}}/detail/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "jobs", "{{job_id}}", "detail", ""]
},
"description": "查询扫描任务的状态和结果详情。\n\n对应 API key: job_detail\n对应方法: TCAClient.wait_for_scan_completion()"
},
"response": []
}
]
},
{
"name": "分析结果",
"item": [
{
"name": "获取扫描结果列表(按job_id)",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/scaninfos/?id={{job_id}}",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "scaninfos", ""],
"query": [{ "key": "id", "value": "{{job_id}}" }]
},
"description": "获取指定 job_id 的分析扫描结果(包含 lintscan/duplicatescan/cyclomaticcomplexityscan/clocscan/qualityscan 等全部维度)。\n\n对应 API key: project_analysis_scan_list\n对应方法: TCAClient.get_scan_info(job_id)"
},
"response": []
},
{
"name": "获取项目概览",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/overview/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "overview", ""]
},
"description": "获取项目分析概览数据。\n\n对应 API key: project_overview\n对应方法: TCAClient.get_project_overview()"
},
"response": []
},
{
"name": "获取最新扫描概览",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/overview/latestscan/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "overview", "latestscan", ""]
},
"description": "获取项目最新一次扫描的概览数据。\n\n对应 API key: project_overview_latest_scan\n对应方法: TCAClient.get_project_overview_latest_scan()"
},
"response": []
},
{
"name": "获取问题列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/codelint/issues/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "codelint", "issues", ""]
},
"description": "获取代码扫描发现的问题列表。\n\n对应 API key: project_issue_list\n对应方法: TCAClient.get_issue_list()"
},
"response": []
},
{
"name": "获取 SCA 扫描结果",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/sca/scans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "sca", "scans", ""]
},
"description": "获取 SCA(软件成分分析)扫描结果列表。\n\n对应 API key: project_sca_scans\n对应方法: TCAClient.get_sca_scan_info()"
},
"response": []
},
{
"name": "获取代码扫描结果列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/overview/lintscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "overview", "lintscans", ""]
},
"description": "获取代码扫描(lint)历史结果列表,用于 overview 为空时的 fallback。\n\n对应 API key: overview_lintscans\n对应方法: TCAClient.get_lint_scan_info()"
},
"response": []
},
{
"name": "获取圈复杂度扫描列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/overview/cycscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "overview", "cycscans", ""]
},
"description": "获取圈复杂度扫描历史结果列表,用于 overview 为空时的 fallback。\n\n对应 API key: overview_cycscans\n对应方法: TCAClient.get_cyc_scan_info()"
},
"response": []
},
{
"name": "获取重复代码扫描列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/overview/dupscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "overview", "dupscans", ""]
},
"description": "获取重复代码扫描历史结果列表,用于 overview 为空时的 fallback。\n\n对应 API key: overview_dupscans\n对应方法: TCAClient.get_dup_scan_info()"
},
"response": []
},
{
"name": "获取代码统计扫描列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{repo_id}}/projects/{{project_id}}/overview/clocscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{repo_id}}", "projects", "{{project_id}}", "overview", "clocscans", ""]
},
"description": "获取代码统计扫描历史结果列表,用于 overview 为空时的 fallback。\n\n对应 API key: overview_clocscans\n对应方法: TCAClient.get_cloc_scan_info()"
},
"response": []
}
]
}
]
},
{
"name": "制品库分析",
"item": [
{
"name": "制品库",
"item": [
{
"name": "获取项目制品库列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/artifact/repos/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "artifact", "repos", ""]
},
"description": "获取项目下的制品库列表。\n\n对应 API key: pt_repo_list\n对应方法: TCAArtifactClient.get_or_create_artifact_repo()"
},
"response": []
},
{
"name": "创建制品库",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"name\": \"{{artifact_name}}\",\n \"artifact_type\": \"{{artifact_type}}\",\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/artifact/repos/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "artifact", "repos", ""]
},
"description": "创建新的制品库。\n\n对应 API key: pt_repo_list\n对应方法: TCAArtifactClient.get_or_create_artifact_repo()"
},
"response": []
}
]
},
{
"name": "分析项目",
"item": [
{
"name": "获取分析项目列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/artifact/repos/{{artifact_repo_id}}/projects/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "artifact", "repos", "{{artifact_repo_id}}", "projects", ""]
},
"description": "获取制品库下的分析项目列表。\n\n对应 API key: project_list\n对应方法: TCAArtifactClient.get_or_create_project()"
},
"response": []
},
{
"name": "创建分析项目",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"name\": \"{{artifact_name}}_project\",\n \"global_scheme_id\": {{scheme_id}},\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/artifact/repos/{{artifact_repo_id}}/projects/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "artifact", "repos", "{{artifact_repo_id}}", "projects", ""]
},
"description": "创建制品库分析项目。\n\n对应 API key: project_list\n对应方法: TCAArtifactClient.get_or_create_project()"
},
"response": []
}
]
},
{
"name": "扫描任务",
"item": [
{
"name": "启动扫描任务",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"artifact_url\": \"{{artifact_url}}\",\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/artifact/repos/{{artifact_repo_id}}/projects/{{artifact_project_id}}/scans/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "artifact", "repos", "{{artifact_repo_id}}", "projects", "{{artifact_project_id}}", "scans", ""]
},
"description": "启动制品库分析扫描任务。\n\n对应 API key: project_scan_list\n对应方法: TCAArtifactClient.start_scan()"
},
"response": []
},
{
"name": "查询扫描任务详情",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{artifact_repo_id}}/projects/{{artifact_project_id}}/jobs/{{job_id}}/detail/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{artifact_repo_id}}", "projects", "{{artifact_project_id}}", "jobs", "{{job_id}}", "detail", ""]
},
"description": "查询制品库扫描任务的状态和结果详情。\n\n对应 API key: job_detail\n对应方法: TCAArtifactClient.wait_for_scan_completion()"
},
"response": []
}
]
},
{
"name": "分析结果",
"item": [
{
"name": "获取 SCA 扫描结果",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{artifact_repo_id}}/projects/{{artifact_project_id}}/sca/scans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{artifact_repo_id}}", "projects", "{{artifact_project_id}}", "sca", "scans", ""]
},
"description": "获取制品库 SCA(软件成分分析)扫描结果列表。\n\n对应 API key: project_sca_scans\n对应方法: TCAArtifactClient.get_sca_scan_info()"
},
"response": []
}
]
}
]
},
{
"name": "源码包分析",
"item": [
{
"name": "源码包",
"item": [
{
"name": "获取项目源码包列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", ""]
},
"description": "获取项目下的源码包列表(代码库接口)。\n\n对应 API key: pt_repo_list\n对应方法: TCASourcePkgClient.get_or_create_source_pkg()"
},
"response": []
},
{
"name": "创建源码包",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"scm_url\": \"{{source_pkg_name}}\",\n \"scm_type\": \"package\",\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", ""]
},
"description": "创建新的源码包。scm_type 固定为 package。\n\n对应 API key: pt_repo_list\n对应方法: TCASourcePkgClient.get_or_create_source_pkg()"
},
"response": []
}
]
},
{
"name": "分析项目",
"item": [
{
"name": "获取分析项目列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", ""]
},
"description": "获取源码包下的分析项目列表。\n\n对应 API key: project_list\n对应方法: TCASourcePkgClient.get_or_create_project()"
},
"response": []
},
{
"name": "创建分析项目",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"branch\": \"{{source_pkg_version}}\",\n \"global_scheme_id\": {{scheme_id}},\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", ""]
},
"description": "创建源码包分析项目。branch 作为版本标识。\n\n对应 API key: project_list\n对应方法: TCASourcePkgClient.get_or_create_project()"
},
"response": []
}
]
},
{
"name": "扫描任务",
"item": [
{
"name": "启动扫描任务",
"request": {
"method": "POST",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"body": {
"mode": "raw",
"raw": "{\n \"artifact_url\": \"{{source_pkg_url}}\",\n \"created_from\": \"api\"\n}",
"options": { "raw": { "language": "json" } }
},
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/artifact/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/scans/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "artifact", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "scans", ""]
},
"description": "启动源码包分析扫描任务,传入源码包文件下载地址。\n\n对应 API key: project_scan_list\n对应方法: TCASourcePkgClient.start_scan()"
},
"response": []
},
{
"name": "查询扫描任务详情",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/main/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/jobs/{{job_id}}/detail/",
"host": ["{{base_url}}"],
"path": ["server", "main", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "jobs", "{{job_id}}", "detail", ""]
},
"description": "查询源码包扫描任务的状态和结果详情。\n\n对应 API key: job_detail\n对应方法: TCASourcePkgClient.wait_for_scan_completion()"
},
"response": []
}
]
},
{
"name": "分析结果",
"item": [
{
"name": "获取扫描结果列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/scaninfos/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "scaninfos", ""]
},
"description": "获取源码包分析扫描结果列表(包含 lintscan/duplicatescan/cyclomaticcomplexityscan/clocscan/qualityscan 等全部维度)。\n\n对应 API key: project_analysis_scan_list\n对应方法: TCASourcePkgClient.get_scan_info()"
},
"response": []
},
{
"name": "获取项目概览",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/overview/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "overview", ""]
},
"description": "获取源码包项目分析概览数据(用于 result_code == 1 的情况)。\n\n对应 API key: project_overview\n对应方法: TCASourcePkgClient.get_project_overview()"
},
"response": []
},
{
"name": "获取最新扫描概览",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/overview/latestscan/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "overview", "latestscan", ""]
},
"description": "获取源码包项目最新一次扫描的概览数据(含质量门禁)。\n\n对应 API key: project_overview_latest_scan\n对应方法: TCASourcePkgClient.get_project_overview_latest_scan()"
},
"response": []
},
{
"name": "获取问题列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/codelint/issues/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "codelint", "issues", ""]
},
"description": "获取源码包代码扫描发现的问题列表。\n\n对应 API key: project_issue_list\n对应方法: TCASourcePkgClient.get_issue_list()"
},
"response": []
},
{
"name": "获取代码扫描结果列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/overview/lintscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "overview", "lintscans", ""]
},
"description": "获取源码包代码扫描(lint)历史结果列表。\n\n对应 API key: overview_lintscans\n对应方法: TCASourcePkgClient"
},
"response": []
},
{
"name": "获取圈复杂度扫描列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/overview/cycscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "overview", "cycscans", ""]
},
"description": "获取源码包圈复杂度扫描历史结果列表。\n\n对应 API key: overview_cycscans"
},
"response": []
},
{
"name": "获取重复代码扫描列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/overview/dupscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "overview", "dupscans", ""]
},
"description": "获取源码包重复代码扫描历史结果列表。\n\n对应 API key: overview_dupscans"
},
"response": []
},
{
"name": "获取代码统计扫描列表",
"request": {
"method": "GET",
"header": [{ "key": "Content-Type", "value": "application/json" }],
"url": {
"raw": "{{base_url}}/server/analysis/api/orgs/{{org_sid}}/teams/{{team_name}}/repos/{{source_pkg_repo_id}}/projects/{{source_pkg_project_id}}/overview/clocscans/",
"host": ["{{base_url}}"],
"path": ["server", "analysis", "api", "orgs", "{{org_sid}}", "teams", "{{team_name}}", "repos", "{{source_pkg_repo_id}}", "projects", "{{source_pkg_project_id}}", "overview", "clocscans", ""]
},
"description": "获取源码包代码统计扫描历史结果列表。\n\n对应 API key: overview_clocscans"
},
"response": []
}
]
}
]
}
]
}